Working with Optical Character Recognition
When you want to find text on your system under test (SUT) and capturing an image of the text is not practical, you can rely on the optical character recognition (OCR) capabilities in Eggplant Functional (EPF) and SenseTalk. OCR is most useful when searching for dynamic text, although you might find many other practical uses.
We highly recommend that you take time to understand the OCR concepts discussed on this page, as well as the Text Properties used with OCR, so that you can make appropriate adjustments to your OCR searches and achieve better search results in your test environment.
Succeeding with OCR: Using The Most Common OCR Properties
SenseTalk includes a number of text properties that allow you to tailor your OCR searches to your situation and environment. Using a tailored OCR search improves the reliability of the search and helps you get the best results. For a full list of OCR properties, as well as information on which properties can be used for reading text vs. searching for text, see Text Properties.
When using properties to tailor your OCR search, it is important to carefully consider which properties to use, and how many. If a search doesn't work, it can be tempting to keep adding properties, but that is not always the best approach. Sometimes removing a property is necessary. Try using them individually first, then add properties as needed. Use the OCR Tuner to play around with properties and see what works. For more about troubleshooting OCR searches, see Troubleshooting OCR.
Each of the following methods might be used to improve OCR recognition or speed up searches. For more information, see Improving the Speed of OCR Searches.
Search Rectangles
It is almost always helpful to add a search rectangle, which limits what part of the screen OCR searches. When OCR searches the entire screen, it is not only slower, but it can also be less accurate because it is more likely to come up with extra possible matches or no matches at all.
Search rectangles are typically defined using images, though coordinates can also be passed to this property. The hot spot of the captured image defines the point used (see Using the Hot Spot for more information on moving this point).
Using images is ideal because it allows the location of the rectangle to be dynamic as elements display in different places on the SUT screen. For instance, the text might appear in a window that does not always display on the same location on the SUT screen. There might be an icon on that window that you can capture an image of, using it as an anchor for your image-defined search rectangle.
If it is not possible to use images to set the search rectangle, you can use screen coordinates. The Cursor Location toolbar icon in the Viewer window is helpful in this endeavor because it shows the current location of the mouse on the SUT. For instructions on customizing your Viewer window toolbar, see Customize the Toolbar.
Example: Reading Dynamic Text from a Website
You might have a test that navigates to the Google Finance page, searches for a specific company, and then reads the stock price. To make sure that OCR reads the value of the price reliably, and nothing else, you can define a search rectangle using images. The code used could be as simple as this:
Log ReadText ("TLImage","BRImage")
You need to capture two images for the above code to work. In this example, you used images TLImage and BRImage to define the top left and bottom right corners of the search rectangle. To capture these images, choose one or more elements of the screen that are stable in relation to the text OCR reads.
This example uses a single element of the screen, the "Company" label.
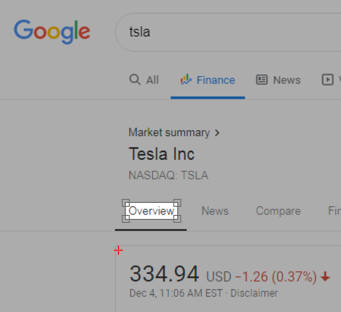
The TLImage capture indicating the top left corner of the image
TLImage is an image of the "Company" label with the hot spot moved to the upper left corner of the area where the stock price is displayed.
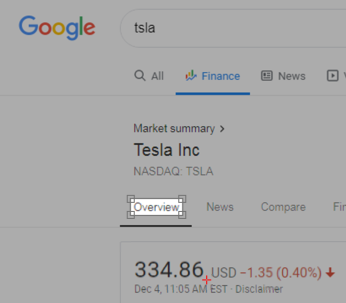
The BRImage capture indicating the bottom right corner of the image
Without even moving the capture area, capture the BRImage with the hot spot moved to the bottom right corner of the area where the stock price displays.
After capturing the images and writing the SenseTalk code, the above example is able to successfully read the stock price for any company in Google Finance.
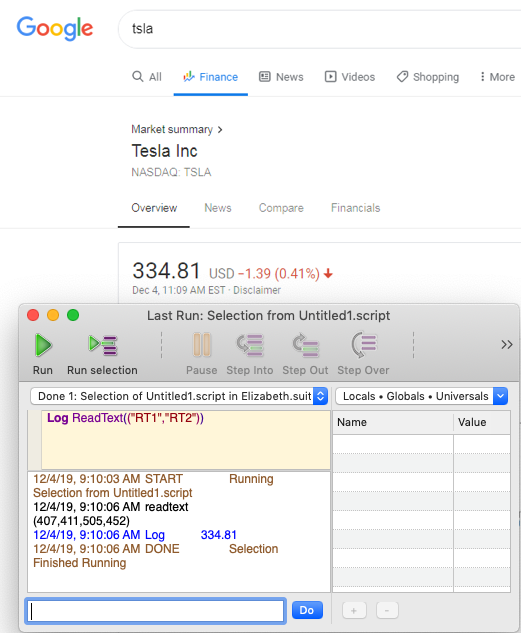
TLImage and BRImage are used to set the search rectangle for a successful ReadText() search using OCR
Contrast
This property causes Eggplant Functional to see in black and white only. Whatever color is being used as the ContrastColor (the background color) turns white, and everything else turns black. For black text on a white background, the code looks like this:
Click (Text: "hello", Contrast:On, ContrastColor: White, ValidCharacters: "hello", Searchrectangle: ("UpperLeftImage", "LowerRightImage"))
In this situation, every pixel close to white (within the standard tolerance range of 45) is turned white, and everything else is read as black. This can help OCR to more clearly read the text.
What it actually sees is this image, free of any anti-aliasing:

What OCR Sees with the Contrast On
To see the text image sent to the OCR engine with your Contrast settings, use the OCR Tuner panel. This panel has a live display showing you what will be sent to the OCR engine for recognition with any combination of contrast-related settings (excluding EnhanceLocalContrast).
When looking for text on a gray background (or another color of medium value), it can get a little more complex. It is good to set the ContrastTolerance a little lower (down to 20 or so), which narrows the number of pixels that OCR might try to turn white. Notice in the image above, a pixel between the “h” and the “e” in “hello” turned black, joining the two letters together. In this instance, OCR was still able to read the letters, but in some other circumstances, this could make the letters even more difficult for OCR to process. This is why it is always a good idea to try things out and see how they work before running a full script.
Click (Text:"hello", Contrast:On, ContrastColor: White, ContrastTolerance: 20)
If the ContrastColor is not set for a Contrast search, then it defaults to the color of the pixel in the top left corner of the search area.
Determining the Background Color
If the background/contrast color is not known, there are two ways to find the RGB values of the background color in a specific location on any platform.
Method 1: Use the Color Picker (Mac)
To use the color picker, follow the steps below:
-
Click the Find Text icon in the toolbar of the remote screen window. This opens the Find Text panel.
-
Click the Text or Background color box. The Colors system panel will display.
-
Click the eye-dropper icon for the color picker, and then hover over the text or background and select the color you want to use for your contrast color setting. Be careful not to select pixels in the anti-aliasing.
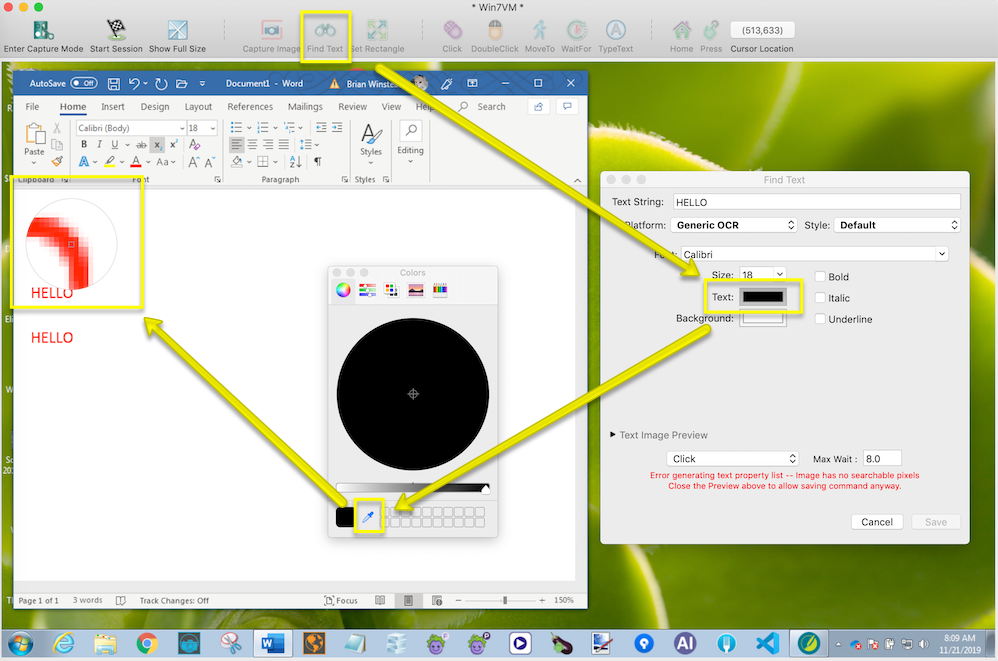
Finding the Contrast Color on Mac, Using the Color Picker
Method 2: Use the ColorAtLocation() function
To use the ColoratLocation() function, follow the steps below:
- Open the Viewer window in Live Mode. If the Cursor Location toolbar icon is not already on the toolbar, see Customize the Toolbar.
- Now do the following to use the
ColorAtLocationfunction. - Move the mouse over the background of which the RGB color value is desired.
- Using the coordinates of the mouse on the SUT, shown in the field of the Cursor Location toolbar icon, run this line of code in the ad hoc do box (AHDB) found at the bottom of the run window, or from a script:
put colorAtLocation(x,y) // where (x,y) refers to the coordinates found in the remote screen window
Running this line of code returns the RGB value for the color at the location specified.
Enhance Local Contrast
Enable this property if you want OCR to automatically increase the local contrast of the text image being sent to the OCR engine. This property may aid recognition when some or all of the text being read has relatively low contrast, such as blue text on a dark background. When Contrast is turned on, this property has no effect, so it is only useful when Contrast is turned off.
Log ReadText(("TLImage","BRImage"), enhanceLocalContrast: On)
ValidCharacters and ValidWords
The ValidCharacters and ValidWords properties restrict what OCR returns. This includes what it considers a match, and what it returns when used to read text.
The value you pass to these properties is given preference by OCR. In essence, you are giving OCR a hint as to what is looking for. For example, if you set ValidWords:"cat" and the word "oat" appears on the SUT screen, OCR might read it as "cat".
ValidCharacters
The ValidCharacters property tells OCR which glyphs to look for, and which to ignore. For example, it can be used to prevent OCR from misreading the letter “O” as the number “0″ or vice versa. This can be done manually for optimal control of your script, or by using an asterisk (*) to automatically set validCharacters to the text being searched for.
ValidCharacters is most useful when reading text in a situation where you don't know the text ahead of time, but need to limit the character set. For instance, this can be used to assist in distinguishing letters from numbers when working with money.
Examples
//Setting the validCharacters manually:
Log ReadText(["TLImage","BRImage"], ValidCharacters:"$£€.,0123456789") -- reads a numeric value including currency symbols
//Using ValidCharacters with a variable:
Put "Charlie" into MyText
Click (Text: MyText, ValidCharacters: MyText)
//Setting the ValidCharacters to the text being searched for, using an asterisk:
Click (Text:"CoDe13v9065", ValidCharacters:"*", SearchRectangle:("UpperLeftImage","LowerRightImage"))
ValidWords
The ValidWords property is similar to ValidCharacters, except that it not only enforces which characters are considers valid, but also the placement of those characters. This is why ValidWords is often used when searching for a specific phrase.
ValidWords overrides the set Language property because it essentially creates a new language library containing only the words provided to ValidWords.
Example
Put "Charlie Brown" into mytext
Click (text: mytext, searchRectangle:("RT1","RT2"), validwords:mytext)
Telling OCR What to Ignore
Working with OCR is all about providing OCR with the right properties for your text search. Most commonly these properties steer OCR toward what it should recognize, but in some cases, it is better to steer it away from improper results by telling it what not to recognize. The below properties specifically tell OCR what to ignore when working with text.
Ignore Spaces
As a property in a text search, IgnoreSpaces can be used to do exactly that—ignore any spaces within the search. For example, this approach could be helpful in a scenario where spacing between characters is not consistent. Sometimes OCR sees spaces where there are not any, or ignores spaces where they exist. Setting the IgnoreSpaces property to ON causes OCR to match “flowerpot” with a search for “flower pot” and vice versa. When this property is used, OCR strips spaces from both the string for which it is searching and the string that it finds to come up with a match.
Click (Text:"flower pot", validCharacters:"*", ignoreSpaces:ON, searchRectangle:("UpperLeftImage","LowerRightImage"))
Ignore Underscores
The ignoreUnderscores property causes OCR text searches to treat underscores as spaces during searches. For example, the string "My_Computer" would match "My_Computer" or "My Computer". The ignoreUnderscores property is on by default because the OCR engine sometimes fails to recognize underscores.
Click (Text:"My_Computer", validCharacters:"*", ignoreUnderscores:ON, searchRectangle:("UpperLeftImage","LowerRightImage"))
Ignore Newlines
A newline is a type of return character that creates a line break. When enabled, ignoreNewlines causes OCR text searches to ignore line breaks, so a search will match a string even if it's broken over several lines. This property is only available for text searches (not available with ReadText).
Click(Text:"Constantine Papadopoulos",IgnoreNewlines:On)-- In the case of a long name like this, it's possible that it could wrap to a second line in the interface of an application under test, but the OCR could still read it with IngoreNewlines enabled.
CaseSensitive
The CaseSensitive property determines whether or not OCR considers case when recognizing text. If you want to validate the capitalization of a text string you are searching for using OCR, enable this property to force text searches to respect case and only find text that matches your search string's capitalization exactly. This property is for searching only and cannot be used with ReadText.
Example
Put "COUPON13995a" into Coupon
MoveTo(Text:Coupon,CaseSensitive:Yes)
ValidPattern
This property takes a regular expression value and returns only characters or words that match the pattern specified. For information on regular expression characters that can be used with SenseTalk, see Using Patterns in SenseTalk. If you want OCR to prefer a pattern but not require it, see PreferredPattern.
There are a number of situations where you might want to work with patterns. One example is when searching for or reading the time off of a date on the SUT.
Examples
Log ReadText(("RT1","RT2"), validPattern:"[0-9][0-9]:[0-9][0-9]") -- Reads the time off of the SUT screen.
put formattedTime("[m]/[d]/[year]") into today -- formats today's date according to the pattern provided to formattedTime()
Click (Text:Today, SearchRectangle:("TL_Date","BR_Date"), validPattern:"[0-9]/[0-9]/[0-9][0-9][0-9][0-9]") -- Clicks the date where found on the SUT screen, opening up a date and time panel. The date format read would be 1/4/2020 with the pattern passed to validPattern in this example.
Specify Languages
The Language can be used to search for text of the specified language or languages. It is not required that you specify a language. However, setting a language gives OCR a guide to work with, because it gives preference to words specified in the dictionary or dictionaries it is provided.
Numerous languages are available in Eggplant Functional by default, and additional languages are available for purchase. For a list of supported languages, see OCR Language Support. You can also create a Custom OCR Dictionary by using properties that overwrite or modify the current dictionary.
Example
If you have characters from different languages in the same sentence, you can specify more than one language.
//String of text displayed on the SUT:
//料理4出6「です。")
//SenseTalk code used to read the multi-Language characters:
ReadText((475,179,608,212), Language:"Japanese,English")
Customize the OCR Engine Dictionary
When you use text-reading functions, you can customize the OCR dictionary to help the OCR engine find the text you’re interested in. SenseTalk includes a number of properties that you can use in a text property list or as options on a readText function call to add or remove words from the OCR dictionary:
- ExtraWords: Set this property to a list of words to supplement the built-in dictionary for the current language.
- PreferDictionaryWords: Enable this property to tell the OCR engine to read each word as a word defined in its dictionaries, if possible. If no suitable dictionary words are found, the engine returns a nondictionary word, using its best interpretation of each character.
- PreferredWords: Set this property to a list of words to supplement the built-in dictionary for the current language.
PreferredWordscan be used for either reading or searching for text. This property modifies the OCR dictionary. For more information, see Customize the OCR Dictionary. - ProhibitedWords: Set this property to a list of words to exclude from recognition. If the engine sees something that looks like one of these words, it falls back to a different interpretation of the characters to get a different word instead. For more information, see ProhibitedWords.
- ValidWords: Set this property to determine the words that can be found by the OCR text engine. The
validWordsproperty overrides theLanguageproperty. - ValidPattern and PreferredPattern also replace the
Language, but with a pattern instead of specific words.
All of the above properties are mutually exclusive. Do not set more than one of these in-line with an OCR command.
You can set these properties for the whole script or for specific commands:
// Set a list of words for the whole script
set the readTextSettings to (extraWords:"ean carner")
put readText(rect, PreferDictionaryWords:yes, prohibitedWords:"can carrier tap")
// Set a list of words in a single command
set rect to the RemoteScreenRectangle
put readText(rect, extraWords:"ean carner", PreferDictionaryWords:yes, prohibitedWords:"can carrier")
Both versions of the code above set the words "can" and "carrier" as prohibited words, effectively removing them from the dictionary. The examples also add "ean" and "carner" as new dictionary words. This example forces the OCR engine to ignore its own best interpretation of the individual letters on the screen and fall back on a less-likely interpretation of the individual letters in order to make dictionary words out of what it sees.
The ExtraWords property creates a custom OCR dictionary, which can be provided command by command or for an entire script, as shown in the examples above. You can also set the ExtraWords dictionary for the whole script by using an external file that lists the desired words:
// Applies the extraWords dictionary to any instance of ReadText() in the script
set the ReadTextSettings to {ExtraWords:file ResourcePath("OCR-Dictionary.txt")}
// Uses an external file to specify the word list for an individual command
put readText((image1,image2), extraWords:file ResourcePath("OCR-Dictionary.txt"))
If you use an external data file, the file must be formatted with a separator between individual words, which can be either a space (white space) character or a newline character.
Using Text Styles
Once you have selected a property set that works for your testing scenario, you have the option to save it as a Text Style. A text style is a saved set of text properties as defined in the Eggplant Functional Text Preferences, OCR Tuner, or OCR Update panel. To create a text style, use one of these panels.
Each style is typically tailored to a particular font or type of graphical user interface element, such as a menu item or title bar that will be encountered repeatedly in an application under test. Text styles can be applied to both OCR searches and ReadText. For more on the difference between reading and searching, see How to Use OCR.
Troubleshooting OCR
OCR is a powerful tool, but there are many ways to use it, and sometimes you have to find just the right combination of properties to get the results you're looking for. Using the OCR Update panel and the OCR Tuner will greatly improve your results.
Familiarizing yourself with the table of OCR Properties found in Text Properties will help with troubleshooting. This page is a great reference to keep handy when working with OCR.
Failed Searches: Enabling the OCR Update Panel and OCR Tuner
When you conduct an OCR search and the OCR engine does not find your text string, Eggplant Functional throws an exception that can cause your script to fail. However, if you enable the OCR Update panel, the OCR Update functionality attempts to apply different properties to the search to see if it can find a match. You can set this functionality to Auto Update, so that it performs without user interaction, or Show Panel, which opens the OCR Update panel on a failed OCR search. For detailed information about using this feature, see The OCR Update Panel.
If you are putting together a new part of your script using OCR or troubleshooting an OCR search that is not working, the OCR Tuner is a useful debugging tool that provides the same property adjustments as the OCR Update panel. Use this panel liberally to adjust OCR properties and see live results of what is being read in the current Capture Area on the Viewer window. Make adjustments as needed, and save your results for use later either by copying the text property list generated, or saving a Text Style. For detailed information about using this feature, see Using the OCR Tuner.
Approaches to Troubleshooting
- Come at your search from a different direction. Remember, OCR can both search for text it is given, or read text off the screen of the SUT. If you're having trouble getting it to find a specific string of text, have it read the text using the
readTextfunction instead and tell you what it thinks is there. This can help you choose the right properties to adjust your search. The Ad Hoc Do Box can be helpful for this; it is a debugging tool built right into the Eggplant Functional Run window. It lets you execute lines of code during your script run without modifying your script. For more information on how to use this tool, see Debugging Scripts. - Adjust your search rectangle. Assuming you have a rectangle set, play around with its location, size, and how close in or far away it is from the text you're trying to read. If you're using
ReadTextat a point instead of in a rectangle, play around with adjusting where the point is. You might also try using a rectangle to define the area to be read more clearly. - Use the OCR Tuner. The OCR Tuner is a diagnostic tool built into Eggplant Functional specifically for working with OCR. When adjusting properties used with OCR text recognition to improve search results, less is more. Before piling on the properties, try them individually or in smaller combinations to obtain the best results. For more information on how to use this tool, see Using the OCR Tuner.
- Play with the contrast settings, including the
contrastColor. A great place to do this is the OCR Tuner, where you can play with the contrast color and see live updates displaying what OCR sees with a given set of contrast properties. Once you know what OCR is seeing, you are better-equipped to fix the problem. - Set a language-related property. Language properties include
ValidCharactersandValidWords, which both force OCR to only recognize the words or characters specified. For instance, if you discover that thereadTextfunction is returning “hello” when the text you want is a password that actually reads “hell0″, specifyingvalidCharacters:"hell0"might improve your results. Specifying an actual language dictionary or working with patterns can also be useful.
- Play with the contrast settings, including the
- Make sure the properties you're using are valid for the type of search being conducted. Reading text off of the SUT and searching for a known text string are different, and some properties only apply to one or the other. For a complete list of all OCR properties and what they can be used for, see the OCR Text Properties Reference Table.
- Start fresh. If you have tried a number of different properties and haven't found anything that works right yet, or haven't tried running the search without any properties, you might remove all of the properties you are currently using and start fresh. First run the search with no properties set, and then try one or two properties at a time. Test different combinations to see what works best with your test scenario.
Common Problem Scenarios
- Multiple Instances of the same text. If there are multiple instances of the same text on the SUT screen and you need to interact with a specific one, try setting a Search Rectangle. The same approaches used for handling multiple instances of the same image on the SUT can be used in this scenario. For more information, see Working with Multiple Instances of the Same Image.
- Difficulty reading or finding spaces. OCR can sometimes have difficulty detecting spaces properly. If you are working with text that contains spaces and OCR is not reading or finding it correctly, but you don't actually need to verify the spacing for the purposes of your test, try using IgnoreSpaces or IgnoreUnderscores. If one or the other of these properties do not work in your scenario, see Alternate Methods below.
Alternate Methods
OCR is a useful tool, but is not right for every situation. Sometimes there are situations where you have dynamic text that OCR cannot read, because it is very low contrast, has an unusual background, or some other reason. In these situations, explore the following options:
- Character Collections. If you are trying to conduct an OCR search for a given text string, consider using a Character Collection. Character Collections are normal image collections, but the images are of individual characters. It sounds like a lot of work, but Eggplant Functional has a special capture mode for character collection. For more information, see Working with Character Collections.
- RemoteClipboard Function. SenseTalk has a
RemoteClipboardFunction for capturing the contents of the SUT clipboard and bringing that information back into your script for use. If you are looking to read text off of the SUT that is selectable, try writing your script to select the text and useRemoteClipboardto bring that information back into your script, as opposed toReadText.
Improving the Speed of OCR Searches
The flexibility of OCR text searches comes with a trade-off: OCR text searches are not as fast as image searches. To keep your scripts running as efficiently as possible, follow these best practices:
- Use a Search Rectangle. Restricting the area of search using a Search Rectangle can greatly improve the speed of your script run. If you can narrow the location of the text you are looking for (e.g., in the task bar or within a particular window), you can set a search rectangle to limit your search to that location. The smaller the size of the area that OCR has to search, the less time it will take to run the search. For more information, see Text Preferences or Searching Part of the Screen.
- Minimize clutter on the SUT. It never hurts to keep a neat SUT (i.e., close unnecessary windows, use a simple desktop background). When your script includes OCR text searches, a neat desktop can save you valuable seconds or even minutes of execution time.