Using XML and Tree Structures in SenseTalk Scripts
SenseTalk's tree structure provides the ability to easily read data in XML format, access and manipulate that data within a tree, and produce XML from this data. A tree is a hierarchical data structure that behaves as both a list and a property list (with some restrictions). As a list, a tree contains items, sometimes called nodes , which are also trees. As a property list, a tree has properties that correspond to attributes of a node in XML terminology.
Trees and Nodes
A tree is a hierarchy that consists of a root node that can have any number of child nodes. Each child node can itself be a tree that can have any number of child nodes and so forth to any depth. Each node (except the root node) has a parent node, which is the tree (or subtree) that contains that node as a child.
In addition to having a parent node and zero or more child nodes, each node can also have a number of properties or attributes, including a tag name.
The basic structure of a tree is like this:
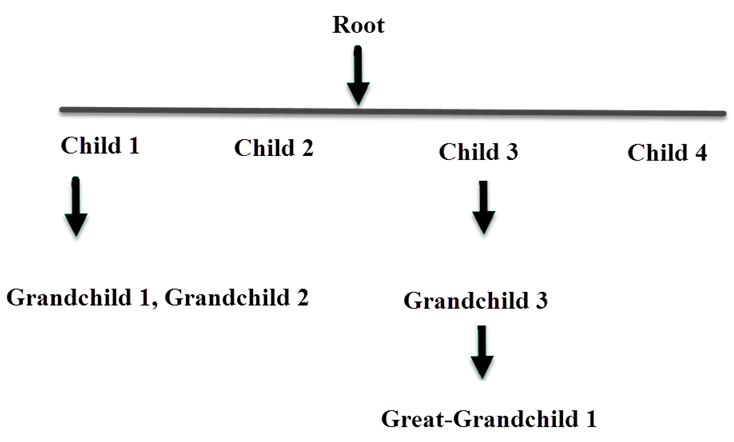
Because every node in a tree can have its own child nodes, each node (together with its children and later descendants) is itself a tree.
Trees and XML
While a tree can be useful for storing various types of hierarchical data, the tree structure in SenseTalk is specifically designed for working with XML documents or XML-based data. eXtensible Markup Language (XML) is a rich, flexible, and complex language that is used as the underlying foundation for a huge variety of data formats in use today.
SenseTalk's tree structure simplifies working with XML documents and data structures, making it easy to access individual values, while providing full access to all parts of a document when needed.
To fully understand trees and their relationship to XML it will be helpful to have at least a basic understanding of the XML structure and some of its terminology. Consider the following example XML document:
<?xml version="1.0?>
<order id ="001">
<customer name="Janet Brown"/>
<product code="prod345" size="6">
<quantity>3</quantity>
<amount>23.45</amount>
</product>
</order>
In the above example, the first line identifies this as a version 1.0 XML document. The second and last lines wrap the rest of the content in order tags. This entire section constitutes either a document node (as shown in the above example) or an element node (if the XML version information is absent) that contains two other elements: customer and product. The customer element has a name attribute but no additional content. The product element has code and size attributes, and also contains two more elements: quantity and amount. Both the quantity and amount elements contain enclosed text, known as text nodes.
We might represent this information in a tree like this:
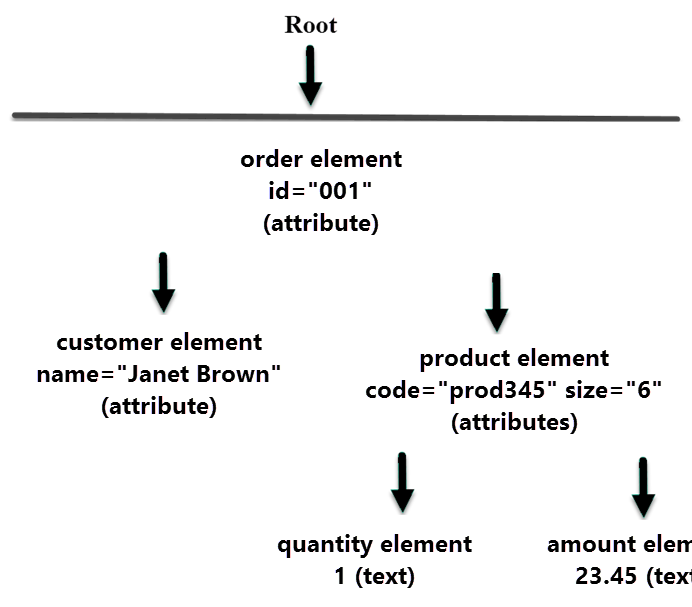
The information in the parentheses indicates the type of node, and the attributes, if any, that are present in that node. In tree form, we can see that the order node has two children (customer and product) and that the product node in turn also has two children (quantity and amount). The quantity and amount nodes each have one child: a text node holding the corresponding value.
Notice that XML data consists mainly of elements (the document node can be treated as a special type of element). Each element has a tag (order, customer, product, and other tags), might have attributes (id, name, code, and other attributes), and might have children. An element's children might be elements, or might be simple text values (3, 23.45). There are other node types as well, including processing instructions and comments, but they are less common and are not shown in this example.
The order example presented here is typical of many XML formats in use today. By combining elements, attributes, and text in a nested structure, XML allows for a wide variety of different formats, and variations within them.
Tree = List + Property List
SenseTalk's approach to working with trees leverages the capabilities inherent in the language for dealing with lists and property lists, by treating a tree as a hybrid of both container types. The children of a tree can be accessed just like the items in a list, and its attributes can be accessed like the property values in a property list.
Some details are different for trees (as discussed below), but on the whole, if you are familiar with working with lists and property lists, you already know most of what you need to work with trees as well. See Lists and Property Lists for details.
Because trees have these characteristics, they might be useful even in situations that have nothing to do with XML, as a hybrid container type that behaves as both a list and a property list.
Working With Trees
Creating a Tree from XML
To load the contents of a URL containing XML data into an internal tree structure within a script, use the as a tree operator:
put url "http://some.site/data.xml" as a tree into myTree
This statement accesses the indicated URL and reads its contents. The as a tree operator tells SenseTalk to treat that data as an XML document and convert it into a tree structure which is then stored in the variable myTree.
It might be more convenient to start with XML contained directly in a script. The as tree operator works equally well for this:
set XMLSource to {{
<order id="001">
<customer name="Janet Brown"/>
<product code="prod345" size="6">
<quantity>3</quantity>
<amount>23.45</amount>
</product>
</order>
}}
// Store the XML information in XMLSource into variable order in tree format
set order to XMLSource as tree
There are references to this order tree in other examples below.
Creating XML from a Tree
Producing text in XML format from the data in a tree is even easier than creating a tree from XML text. Whenever a tree structure is used as text, it automatically creates an XML representation of the tree's contents. To make an XML file from a tree, for example, use this syntax:
put myTree into file "/path/to/aFile.xml"
Accessing Tree Content
The children of a tree can be accessed just like the items of a list. The following examples use the information from the as tree structure example, above:
put item 1 of order
Running the above command results in the following:
The attributes of a tree can be accessed just like the properties of a property list:
put order.id
Running the above command results in the following: 001
Combining items and properties provides access to more deeply nested data:
put the code of item 2 of order
Running the above command results in the following: prod345
Accessing Tree Nodes Using XPath Expressions
XPath is a standard mechanism for accessing content in XML documents. It provides a way to describe the node or set of nodes that you are interested in, and extracting the desired information for you. SenseTalk supports this powerful mechanism through node expressions, which let you access content within a tree by tag name:
put node "*/customer" of order
Running the above command results in the following:
Node expressions can describe a path to a nested node of a tree:
put node "*/product/amount" of order
Running the above command results in the following:
A special text property helps to extract just the content of a tree or node:
put the text of node "*/product/amount" of order
Running the above command results in the following: 23.45
Use all nodes or every node to return a list of every node of a tree that matches an XPath expression:
put all nodes "*/product/*" of order
Running the above command results in the following:
(
put every node "*/*/amount" of order
Running the above command results in the following: (
The nodePath function returns an XPath expression for a particular node within a tree:
put nodepath of item 2 of item 2 of order
Running the above command results in the following: (/order[1]/product[1]/amount[1])
A node expression (but not all nodes) can also be used as a container that can be stored into to alter the contents of the tree:
put 7 into node "*/product/quantity" of order
Running the above command results in 7 replacing 3 as the quantity value. To verify that the change worked, run the following command:
put node "*/*/quantity" of order
Look for the following output to verity that the 3 was replaced by 7:
XPath expressions include many different options for accessing specific nodes, only a few of which are shown here. For more details about using XPath, see XPath Definition or the full specification at XML Path Language (XPath).
Deleting Tree Nodes with Node Expressions
Tree nodes can be deleted using a node expression (previously only item expressions worked with the delete command for deleting tree nodes):
delete node "product/description" of order
GatherNamespaces Command and Function
Behavior: The GatherNamespaces command and function scans a tree structure for namespace definitions in all sub-nodes within the tree, and copies all of those namespace definitions to the top level of the tree. Node expressions that specify a node using a name that includes a namespace prefix may fail if that namespace is not declared in the top level (root node) of the tree. Using GatherNamespaces to copy namespace definitions to the root of the tree makes it possible to locate nodes within the tree using namespace-qualified names that might otherwise fail.
Command Usage
When you call GatherNamespaces as a command, you must pass the tree by reference to allow the function to make changes to the tree."
Command Syntax:
GatherNamespaces treeReference
Example:
gatherNamespaces myTree by reference // pass the tree by reference to allow changes
put node “//web:table” of myTree into myTableNode // namespace-qualified name should now be successful
Function Usage
When called as a function, GatherNamespaces returns a modified copy of the tree.
Function Syntax:
gatherNamespaces( aTree )
{the} gatherNamespaces of aTree
aTree . gatherNamespaces
Example:
put node “//namespace:name” of myTree.gatherNamespaces // call gatherNamespaces so the node reference will succeed
Three Special Properties: _tag, _children, _attributes
There are a number of property names (all beginning with an underscore character) that have special meaning in a tree. The three most important ones are:
-
The _tag property refers to the tag name of an element.
-
The _children property refers to the children of a tree. Its value is a normal list containing all of the child trees.
-
The _attributes property refers to the attributes of a tree. Its value is a normal property list whose keys and values are the names and values of all of the tree's attributes. Through the
_attributesproperty it is possible to access any attributes of a tree, including those that have the same name as one of the special tree properties.Along with any standard attributes, when namespaces are defined for an element, the _namespaces property will contain the namespace definitions for that element. Its value is a property list in which each key is a name prefix, with the value being the associated namespace URI.
In addition to these properties, a Document node can also have an _xmlinfo property, described below in Converting a Tree to Text.
Creating an Empty Tree
To create a tree entirely within a script rather than starting from an existing XML document, start with an empty tree to which content can be added:
put an empty tree into order
The tree produced by this statement is ready to accept children or attributes. It does not have a tag name, so a recommended second step would be to set its _tag property:
set order's _tag to "order"
Setting XML Attributes of a Tree
A tree's properties correspond to the "attributes" of an XML element. They are containers, and can be set just like the properties of a property list are set:
set order's id to "001"
The only limitations on setting a tree's properties are as follows:
-
Values are always converted to text when they are set.
-
Property names must conform to the rules for standard XML identifiers (which are the same as for identifiers in SenseTalk:
- They must begin with a letter or underscore.
- They must contain only letters, underscores, and digits.
Adding Children to a Tree
The children of a tree are accessed like items in a list. To add a new child, use the insert command:
insert << <customer name="Jane Doe"/> >> into order
To verify that the change worked, run the following command:
put every node "*/customer" of order
Look for the following result: (
Children must be trees, or values that can be converted into a tree. Values are converted automatically when they are added to a tree, using the same rules as the tree function, described later in this section. Only nodes that have a nodeType of Document, Element, or DTD can have children. Other types of nodes do not have children and do not behave like lists.
Converting a Tree to Text
When a tree is accessed as text (such as when it is displayed by a put command), SenseTalk converts it automatically to a text representation in XML format. By setting the treeFormat's prettyPrint to true or false you can control whether or not the XML will be formatted on multiple lines with indentation for easier reading by a person. By default that property is set to true. The standardFormat() function can also be used to format a tree as text.
If the tree has document-level information (as defined by the _xmlinfo property) it will be used in generating the text representation of the tree. The _xmlinfo property can only be set at the top level of a tree (not a sub-tree), so inserting a tree as a sub-tree of another will discard its document-level information. The _xmlinfo property is a property list that can include the following document-level properties:
CharacterEncoding– if set, this should be the name of a valid XML encoding (see Character Sets (IANA) for a list of valid encoding names – these are not the same as SenseTalk's string encoding types).DocumentContentType– must be one of XML, XHTML, HTML, or Text. This controls some aspects of the text representation that will be generated for that tree.MIMEType– should be set to a valid MIME type (see Media Types (IANA)).URI– the Uniform Resource Identifier (usually a URL) associated with that document.Version– should be either1.0or1.1to indicate the XML version.
In addition, the _xmlinfo can also include two lists of tree nodes representing comments or processing instructions which precede or follow the root element of the document:
Head– a list of comments and processing instructions that precede the root elementTail– a list of comments and processing instructions that follow the root element
Creating a Tree from a Property List
It might be convenient to represent information in a script in the form of a property list, then convert it to a tree in order to produce XML output. SenseTalk's tree function (or asTree() or as a tree operator) supports property lists in several formats to make this convenient.
In the full standard format, the property list can include these special properties (and values):
- _tag or _element (tag name of an element);
- _attributes (property list of attributes of an element node);
- _children (list of child nodes);
- _namespaces (property list of name prefixes and associated namespace URIs);
- _text (contents of a text node);
- _comment or -- (contents of a comment node);
- _processingInstruction or _pi (contents of a processing instruction node);
- ? followed by processing instruction name (body of a processing instruction node);
- _XMLinfo (property list of special XML document attributes).
Here is a simple example using this approach:
put {_tag:book, _children:"The Rose"} as tree --> <book>The Rose</book>
For situations where XML attributes are not needed, a simplified format can be used:
put {book:"The Rose"} as tree --> <book>The Rose</book>
Some XML formats use attributes but no content, which can be done like this:
put tree(_tag:"pg", _attributes:{id:43}) --> <pg id="43"></pg>
A simplified format can also be used in this case:
put tree(_tag:"pg", id:43) --> <pg id="43"></pg>
The rules for converting a property list to a tree can be summed up in this way: If there is only a single property, and it is not one of the special properties, that property name is taken to be the name of an element, and its value represents that element's children. If a property list has a _tag or _element property, it will produce an element node. In this case, if there is no _attributes property then other properties that do not have special meaning are assumed to be attributes.
Creating a Tree from a List
It is also possible to convert a list to a tree using the tree function (or asTree() or as a tree operator). When converted in this way, a list becomes an unnamed tree (with an empty tag). This also applies to nested lists or lists within property lists that are being converted.
Converting a Tree to a Property List
A tree can also be converted to a property list, by using the as operator. For example:
put "<zip>80521</zip>" as tree as object --> {zip:["80521"]}
SenseTalk will use a simplified form for the property list if it can. To produce a standard format in all cases, set the treeFormat's useStandardFormat property to true:
set the treeFormat's useStandardFormat to true
put "<zip>80521</zip>" as tree as object --> {_children:[{_text:"80521"}], _tag:"zip"}
Tree Comparisons
When two values are compared for equality (using the is or = operator), they are ordinarily compared as text. Only when both values are trees (in tree format, not a property list or XML text representation of a tree) are they compared as trees. You can force comparison as trees by specifying as tree for any non-tree value.
When one tree is compared to another, the two trees will be regarded as equal if they have identical contents, including identical children and properties. However, if two trees are nearly identical such that the only difference between them is that one tree has a version or characterEncoding property with the default value and the other tree lacks such a property, then the two trees will be treated as equal.
Working with Node Types
Each node within a tree has a node type. The nodeType property of a node returns a node's type:
put order's nodeType --> Document
put the nodeType of item 1 of order --> Element
The types of nodes that can be present in a tree include Document, Element, Text, DTD, ProcessingInstruction, and Comment. A node's type cannot be changed. To test whether a node is a particular type, the is a operator also can be used:
put order is a Document --> True
Only Document, Element, and DTD nodes can have children. Attempting to add a child node to any other type of node will result in an error.
Global Properties
In addition to the functions described below, there are two SenseTalk global properties you can use to govern certain aspects of tree behavior:
The TreeFormatThe TreeInputFormat
These global properties are defined on Global Properties for XML and Trees.
Tree Functions
Tree, AsTree Functions
Behavior: The tree or asTree function (called by the as a tree operator) returns the value of its parameter converted to a tree.
Syntax:
{the} tree of factor
tree( expr )
{the} asTree of factor
asTree( expr )
When the tree function is called with a parameter that is a property list (object) that has an asTree property, the value of that property is used. If the object has an asTreeExpression property, the value of that property is evaluated as an expression (equivalent to calling the treeFromXML() function) to obtain the tree value. If the object has neither of these properties, an asTree function message is sent exclusively to the object and its helpers to obtain the tree value.
If the parameter is an object, but does not supply a tree representation of itself in any of the above ways, it is interpreted as a direct property list representation of a tree structure or a node. The property list can include these special properties (and values):
- _tag or _element (tag name of an element);
- _attributes (property list of attributes of an element node);
- _children (list of child nodes);
- _namespaces (property list of name prefixes and associated namespace URIs);
- _text (contents of a text node);
- _comment or -- (contents of a comment node);
- _processingInstruction or _pi (contents of a processing instruction node);
- ? followed by processing instruction name (body of a processing instruction node);
- _XMLinfo (property list of special XML document attributes).
See Creating a Tree from a Property List for more information.
If the parameter is not an object and it is not already a tree, its string value is evaluated as an XML expression (equivalent to calling the treeFromXML() function) to obtain the tree value.
If the parameter includes a version property, the resulting tree object will be a Document type node, otherwise it will be an Element node.
Examples:
put file "configuration.xml" as a tree into config
put asTree("<a>Contents</a>") --> <a>Contents</a>
put { _tag:book, _children:"The Rose" } as tree --> <book>The Rose</book>
put tree(_tag:"page", num:8) --> <page num="8"></page>
See Also: Conversion of Values and the as operator in Expressions.
TreeFromXML, TreeFromHTML Functions
Behavior: The treeFromXML function evaluates a text value as XML and returns a tree. The treeFromHTML function evaluates a text value as HTML and returns a tree representation of that HTML content.
Syntax:
{the} treeFromXML of factor
treeFromXML( expr )
{the} treeFromHTML of factor
treeFromHTML( expr )
The treeFromXML function tries to evaluate its parameter as XML text. If the text is valid XML, it is parsed and the resulting tree returned. The tree returned will be a Document node if document-level information such as the XML version is present in the text, or an Element node otherwise. If the text is not valid XML, the returned tree will represent an XML text node rather than an element or document, and the result will be set to a warning message.
Similarly, the treeFromHTML function tries to evaluate its parameter as HTML text. If the text is valid HTML, including a valid fragment (rather than a full document) it is parsed and the resulting tree returned. If the text is not valid HTML, an exception will be thrown.
Examples:
put treeFromXML(xmlText) into aTree
put treeFromHTML(htmlText) into htmlTree
DocumentTreeFromXML, DocumentTreeFromHTML Functions
Behavior: The documentTreeFromXML and documentTreeFromHTML functions evaluate a text value as either XML or HTML respectively and return a tree representation of that content. The returned value will always be a Document node rather than an Element node (assuming there are no errors).
Syntax:
{the} documentTreeFromXML of factor
documentTreeFromXML( expr )
{the} documentTreeFromHTML of factor
documentTreeFromHTML( expr )
The documentTreeFromXML function tries to evaluate its parameter as XML text. If the text is valid XML, it is parsed and the resulting tree returned. The tree returned will be a Document node regardless of whether document-level information such as the XML version is present in the text. If the text is not valid XML, the returned tree will contain the text as a text node, and the result will be set to a warning message.
If the standardNodeExpressions is turned off, use "as document tree" instead of "as tree" to parse XML into a tree and ensure standard behavior of node expressions for that tree.
Similarly, the documentTreeFromXML function tries to evaluate its parameter as HTML text. If the text is valid HTML, including a valid fragment (rather than a full document) it is parsed and the resulting Document tree returned. If the text is not valid HTML, an exception will be thrown.
Examples:
put documentTreeFromXML(xmlText) into docTree
put documentTreeFromHTML(htmlText) into htmlDocTree
STTreeVersion Function
Behavior: The STTreeVersion function returns the current version number of the STTreeNode xmodule.
Syntax:
the STTreeVersion
STTreeVersion()
Examples:
put STTreeVersion()