Images
Image recognition, along with OCR, is a primary automation approach within Eggplant. This allows for simple, non intrusive automation to test the UI and importantly, the end user experience. With image recognition, the key aspects to consider are the consistency of the images that are captured, and any potential maintenance overhead.
Key Points:
- When possible, capture images of icons and logos
- Maintenance, ensure image captures are flexible to underlying UI changes
- Pre-empt future project requirements, where different resolutions may be required
Image Capturing
In this example, the goal is to capture the Keysight logo, in its most unique form to ensure that in future iterations - if the Keysight logo was to either move or the background colour of the website to change - our capture would still be usable.
Here we can see that not only have we caught part of the website menu, we have also captured part of the browser UI.
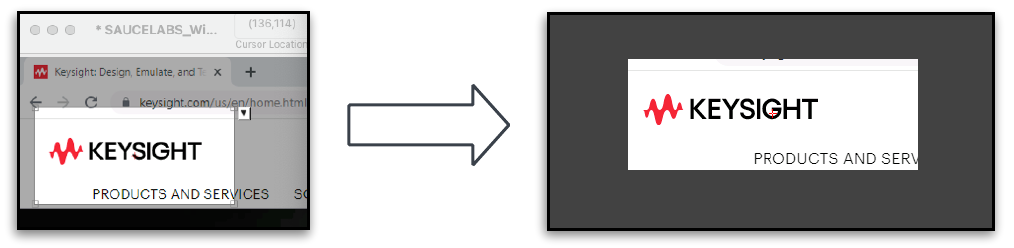
This causes the following risks:
- The image will only be found on a specific browser.
- The placement of the image has to be exact to the navigation menu and browser UI.
- Background colour will always have to be white.
In the example below, we've remedied the above issues by tightening the capture area directly around the logo. As you can see, there is no other content that will risk the image during future releases.
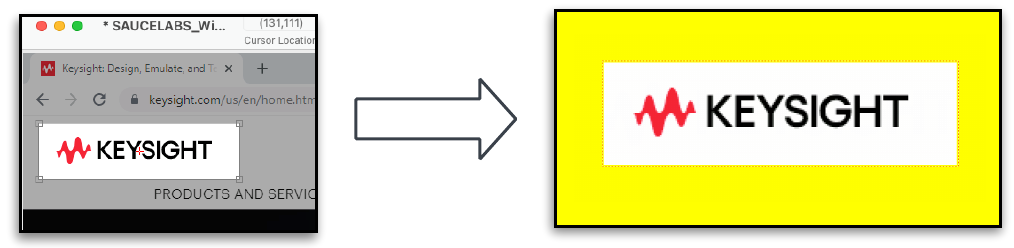
We've gone further by altering the image properties. Help on using the image editor can be found here.

Image Folder Structure
Structuring your image library not only promotes having a logical naming convention and file hierarchy of the images, but it can also be used as a technique to make your code more modular, as described in the good example below.
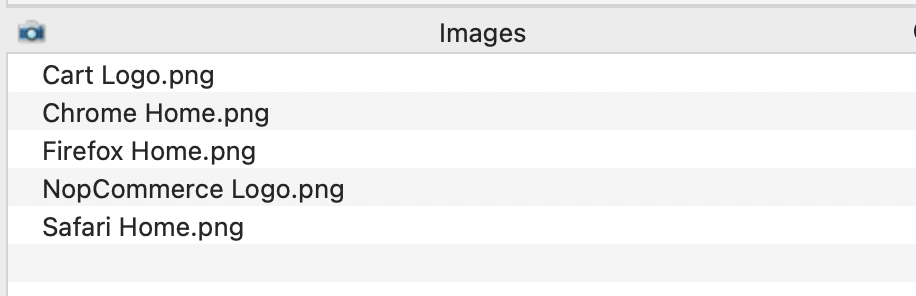
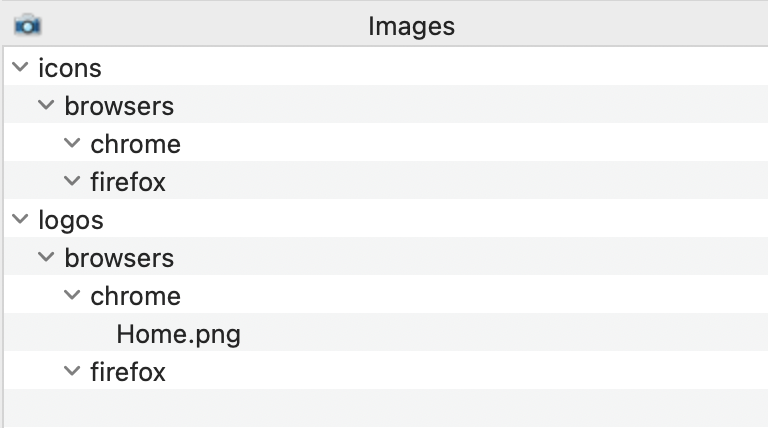
In the good example above, we can see that the images are logically stored in directories. This can be utilised when combining parameters in your code to select the correct image to use.
In the code below, a parameter browser is used to select the correct image from the library.
If the browser variable was equal to 'Chrome' it would select the image from the 'Chrome' directory, whereas if it was 'Firefox' it would select from the 'Firefox directory'
waitfor 20, image:"logos/browsers/" & browser & "/Home"
Handling Multiple Resolutions
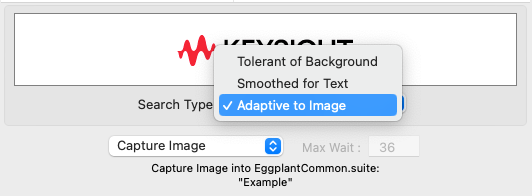
Projects often have the requirement to test the same application across various form factors. To ensure you only need to capture one image to facilitate this per device, the 'Adaptive To Image' image search function facilitates this.
The following steps will guide you to do this:
- When saving an image, the Capture Image panel gives you a choice of search types. The default will be either Tolerant of Background or Smoothed for Text (when text is identified)
- By changing the image search type to Adaptive To Image, this effectively allows Eggplant to see the image as a whole instead of comparing pixels and only requiring us to capture 1 image for the multiple resolutions that may be required.
The video below is an example of when the adaptive setting is not applied. We can see, the image struggles to be found on the secondary device, however, when applied the image is identified on both screens: