OCR
The other key automation technique, is OCR (Optical Character Recognition) e.g. text searches. OCR can offer a more robust and easily maintainable alternative to using Images.
As with Images, there are key aspects we can use to better utilise OCR.
- Case Sensitivity and other OCR properties
- Targeted search areas to reduce the search space.
- Short Hard Waits during a page load.
Case Sensitivity
Turning Case Sensitivity on ensures that the OCR engine is searching for an exact match. This is a simple and quick way to reduce the number of false positives, improving the reliability of our scripts.
We can ensure that case sensitivity is set as default, either through the Eggplant Preferences or by the use of textStyles/properties in the OCR search .
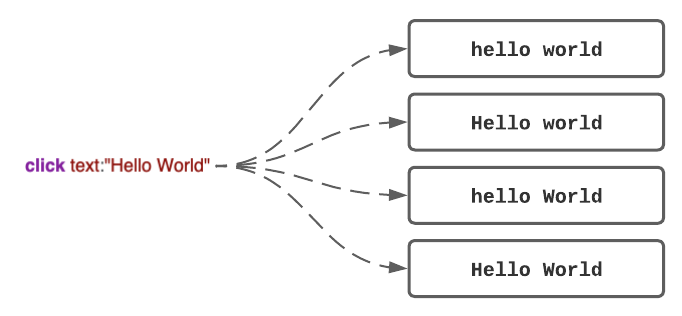
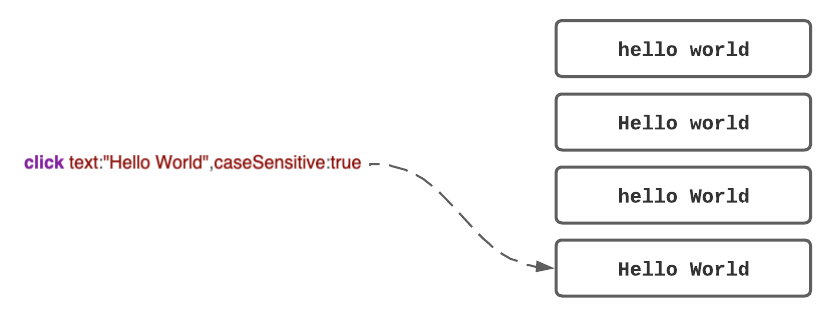
With the examples below, the lefthand line of code will match with all 4 instances of 'Hello World'. This solution will end up with a non-specific search or a false positive in the automation. Simply adding a caseSensitive property to the search reduces the matches to 1, ultimately improving the accuracy. We suggest you set your Eggplant Preferences to use caseSensitivity as a default.
Transitional Waits
Eggplants OCR engine, will read from the top left of the screen to the bottom right. Each time a search is executed, there will be processing involved which naturally take time. To ensure we are not over using the engine during unnecessary events e.g. page transitions, event animations etc., pausing the engine between a sequence of OCR searches will optimise the automation speed.
This can be achieved by short hard waits: i.e. wait 2 seconds:
|
As can be seen from the video below, we have the left side running with no pause, while the right side has a pause between searches. The approach shows the execution is 3 seconds faster with a transition wait attached.
Reduce Search Area
Reducing the OCR search space has 2 main benefits:
- Improving the OCR speed by reducing and simplifying the area the OCR has to interpret.
- Removing the risk of false positives and incorrect reads.
By limiting the search area to the key automation area, we can significantly reduce the risk of false positives and dramatically increase the execution speed.
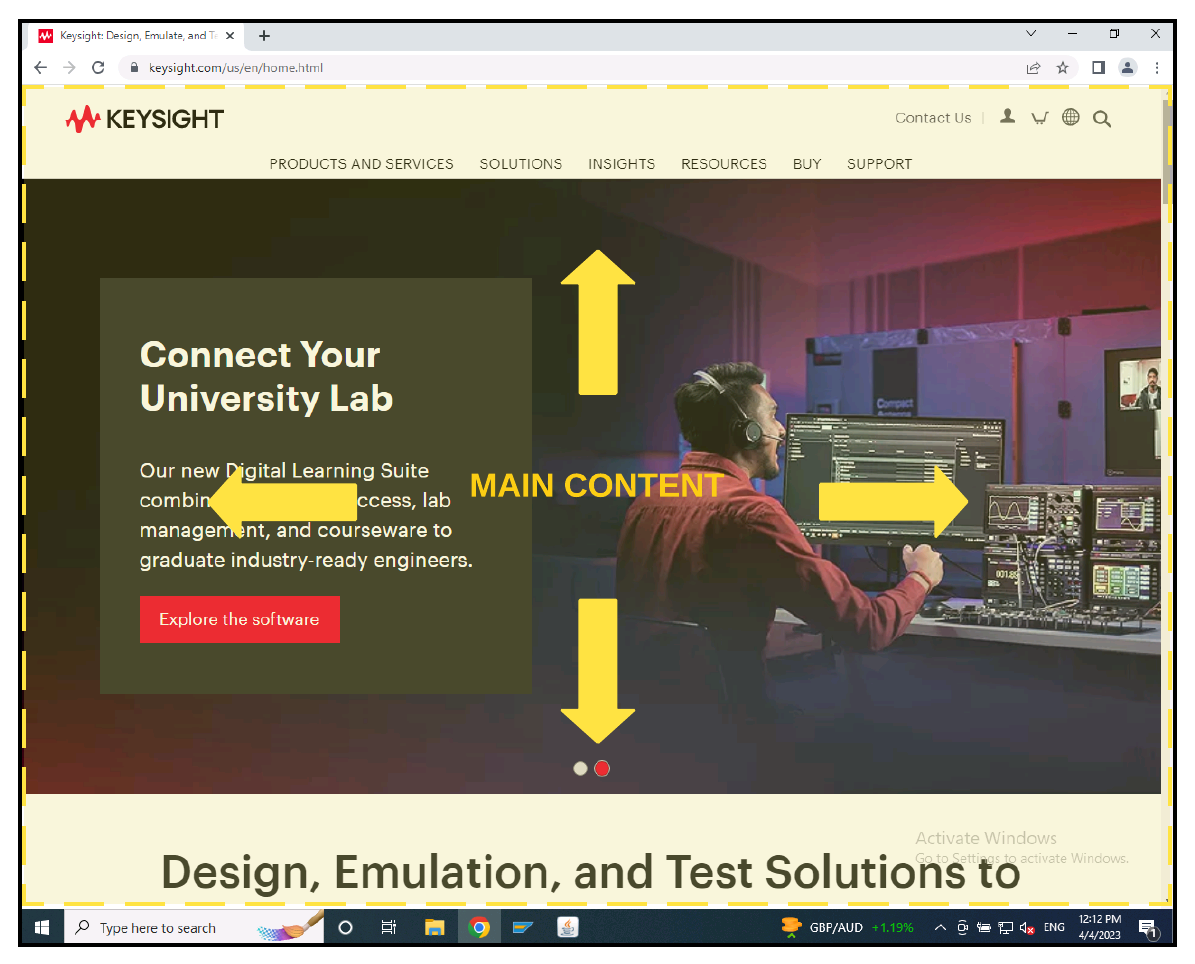
A simple example of this is outlined below. As we are testing the web application, and not the browser or the operating system, we can limit our search area, using a search rectangle that only focusses on the rendered content. As a result, the OCR engine is optimised to only search in areas we are interested in.
Further, applications typically have consistent colour schemes. If we isolate the search area, to the AUT, we are simplifying the colours and contrast ratios allowing an easier interpretation for OCR.
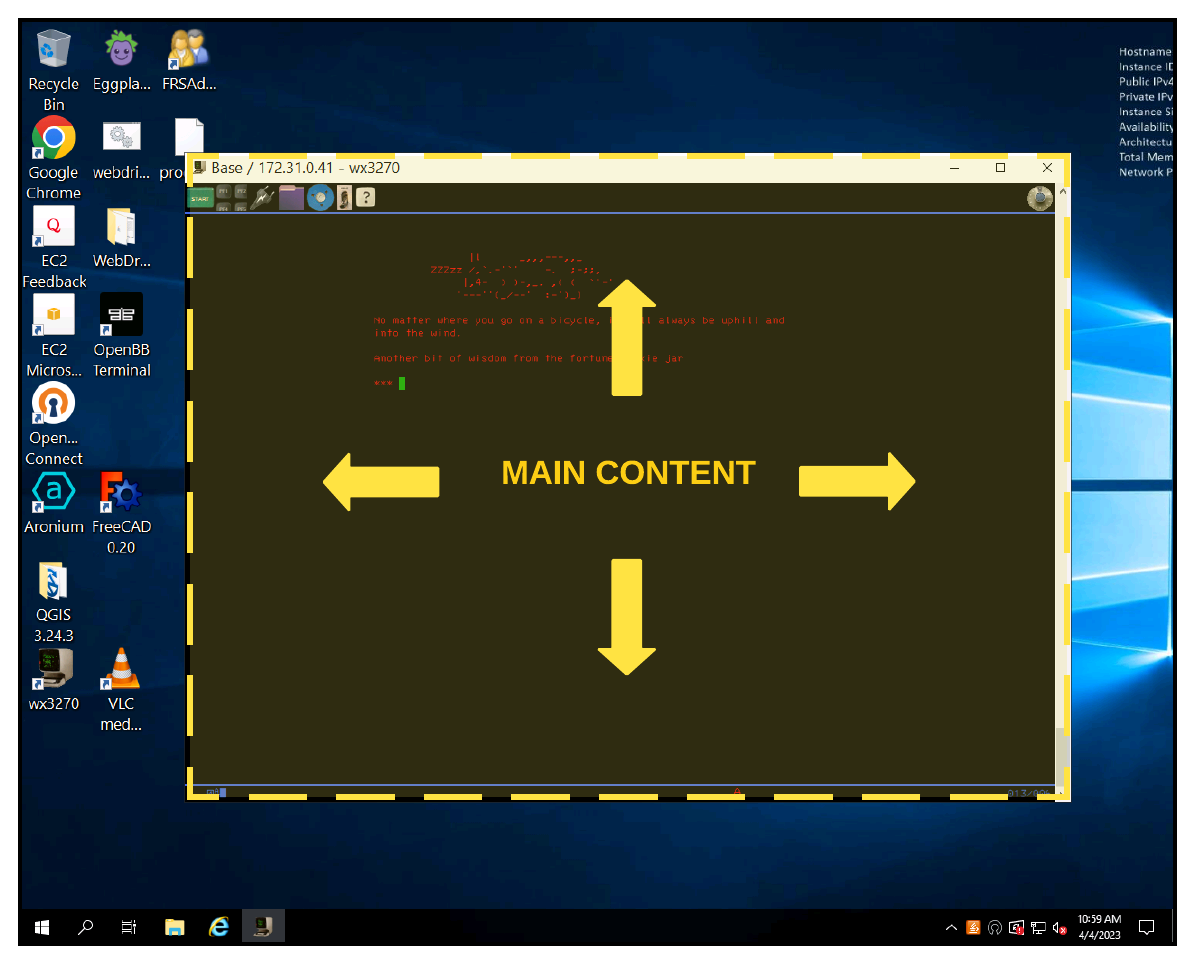
As we can from the screenshots below, the areas in yellow indicate search areas specific to the AUT. In one case a web application and the other a mainframe/terminal app.
Reducing the Search Areas of the AUT
Going further, the AUT can be itself, broken down into logical panels based on reoccurring layouts. However be cautious to not over engineer the search spaces and focus on consistencies or problem scenarios eg.:
- Main content
- Top and side menus
- Popups
The example below, shows the separation of areas against Salesforce Lightning, where we have separated the main navigation, content and the popup / new window for data entry:
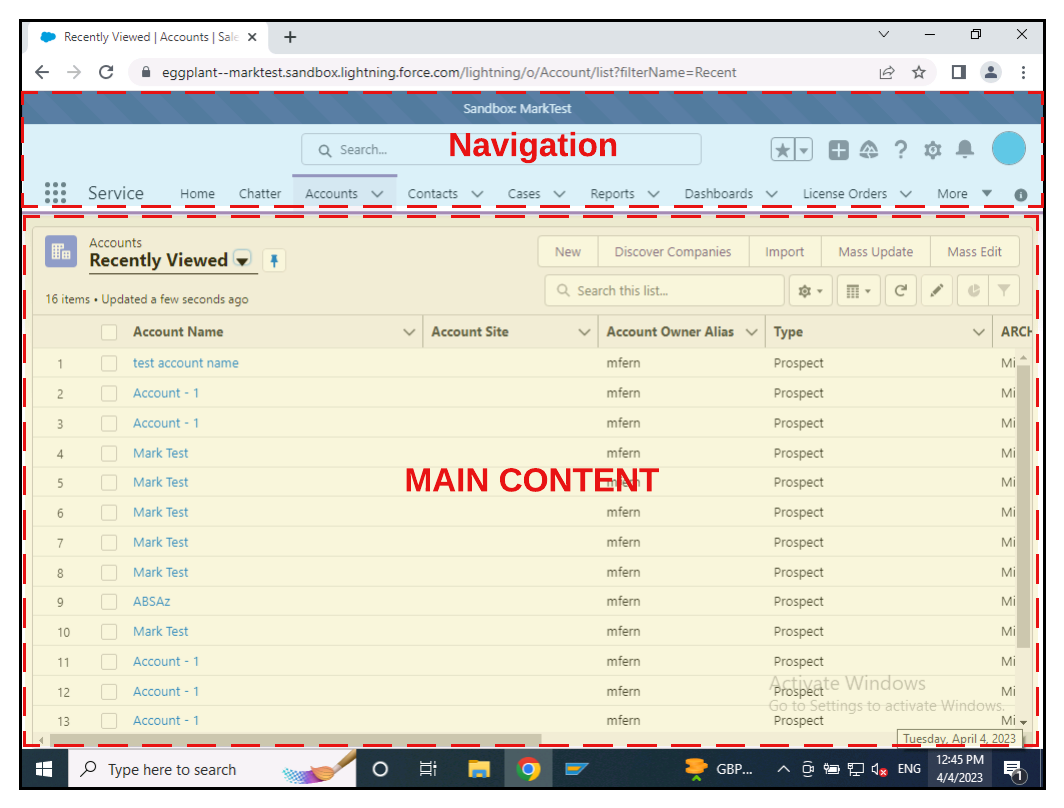
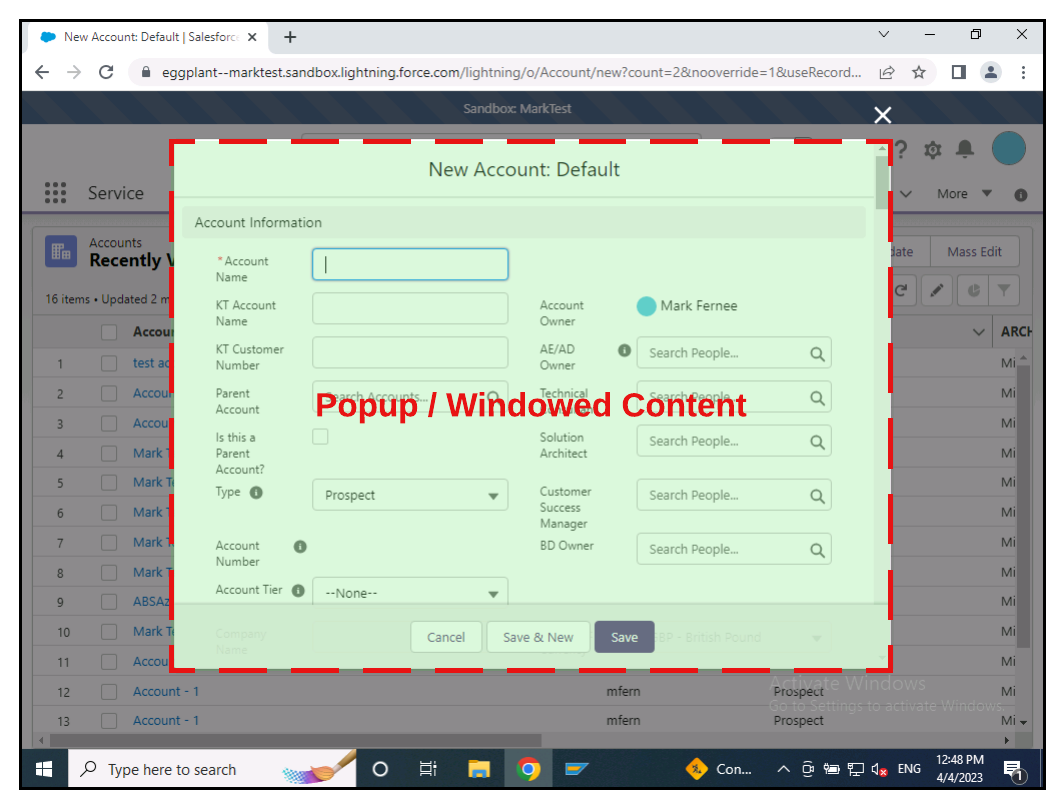
Separating the Search Areas
Inline Properties
There are two ways to set SearchRectangles and other Global Eggplant Properties. The first is to explicitly set the searchRectangle in the code.
The drawback here, is that every scenario inherits this specification and to change the search area - a constant maintenance cycle of setting, resetting the searchRectangle is required.
|
A cheaper and scalable solution would be to identify the lines of code, where a restricted search area is required and use the inline searchRectangle property for OCR (and also Image) searches:
|
An inline property is only specific to that line of code and will not apply any where else. Using suite wide properties (eg. the searchRectangle, the Text Style etc) are useful for multiple blocks of events which needs a tailored set of properties (eg. table validation, data entry etc).