OCRチューナーの使用
Eggplant Functionalの光学文字認識(OCR)検索エンジンには、OCR検索を改善するのに役立つ多くのパラメーターが含まれています。
OCRチューナーは、OCRプロパティ設定を変更し、結果をリアルタイムで確認することができるデバッグツールです。これにより、特定の状況でどのOCRプロパティを使用するかについて、必要な情報を得て意思決定することができます。これらのOCRプロパティに対する調整を行った後、設定をテンプレートスタイルとして保存し、後で同じ設定を再利用することができます。テキストスタイルについての詳細は、テキスト設定をご覧ください。
OCRチューナーが提供するOCRテキストプロパティのビューは、テキスト設定やOCRアップデートパネルでも見ることができます。
1. OCRチューナーパネルの起動
-
OCRを見つけるためにチューニングしたいテキストの周囲にキャプチャエリアを設定します。
-
OCRチューナーを開きます。OCRチューナーは、ビューアウィンドウがキャプチャモードにあるときに開くことができます。ビューアウィンドウがキャプチャモードにあるときにSUTスクリーンを右クリックするか、キャプチャエリアの右上隅にあるドロップダウンアローをクリックするか、ツールバーのOCRチューナーボタンをクリックします(この表示にはツールバーをカスタマイズする必要があります)。
-
OCRチューナーパネルが表示されます。
2. OCRプロパティの調整
このパネルは試行錯誤のために作られていますので、必要に応じてプロパティを変更し調整し、目的の結果を得ることができます。
一度に1つのプロパティを検索に適用し、各プロパティが個別に結果にどのように影響を与えるかを確認します。次に、あなたのシナリオで役立つプロパティを組み合わせて、それらがどのように相互作用するかを確認します。多数のプロパティ設定を一度に適用すると、実際にどの設定が望む結果を達成するのに役立っているのかを把握するのが難しくなります。詳細は、OCRのトラブルシューティングをご覧ください。
このパネルの各セクションについては以下に概説します。このパネルの個々のテキストプロパティオプションについての詳細な情報は、テキストプロパティを参照してください。
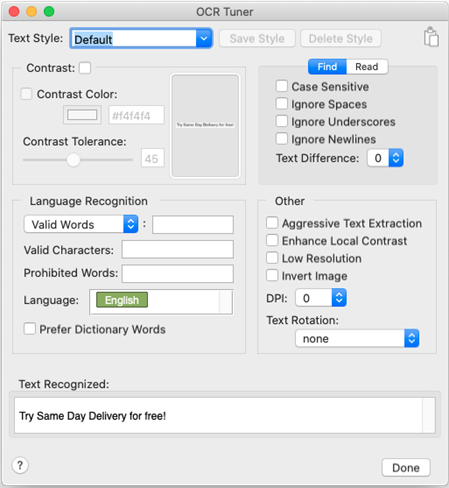
テキストスタイル
テキストスタイルは、Eggplant Functionalの テキスト設定、OCRチューナー、またはOCR更新パネルで定義されたテキストプロパティの保存セットです。各テキストスタイルは、通常、テスト対象のアプリケーションで繰り返し遭遇する特定のフォントやGUI要素(メニューアイテムやタイトルバーなど)に特化したものです。テキストスタイルは、OCR検索とReadText()の両方に適用することができます。読み取りと検索の違いについての詳細は、OCRの使用方法をご覧ください。
パネルはデフォルトスタイルが選択された状態で開きます。一度この下のセクションでOCRプロパティを変更すると、現在のスタイルが変更されます。この新しいスタイルを保存するには、Text Styleドロップダウンメニューの「デフォルト」を選択し、名前を変更するか、または上書きしたいスタイルを選択します(デフォルトスタイルは変更可能)。Save Styleをクリックします。
現在選択されているスタイルを削除するには、Delete Styleをクリックします。このオプションはデフォルトスタイルが��選択されているときは無効になります。
このセクションの右側にはコピーアイコンがあります。これは、以下のセクションで設定した現在のテキストプロパティをスクリプトで使用するためにコピーするために使用できます。詳細は、プロパティ設定の保存またはコピーを参照してください。
コントラストセクション
Contrastセクションでは、Contrastプロパティと関連プロパティを設定し、作業することができます。Contrast設定は、システムアンダーテスト(SUT)の画像をOCRが取得し、それをOCRエンジンが認識する前に白黒に変換します。このインタラクティブなセクションには、右側にライブ更新エリアがあり、現在の検索矩形をビューアウィンドウで描画したものと、現在のContrast設定でOCRエンジンに送信されるものを表示します。
-
コントラスト: {#contrast}分析のために OCR に送信される前に、SUT ディスプレイが高コントラストの 2 色画像に変換されるかどうか。
contrastがオンの場合、「コントラスト カラー」と呼ばれる色 (ContrastColorプロパティを使用して設定できます) が SUT ディスプレイの原色とみなされます。他のすべての色は 2 次色として扱われます。テキストはどちらの色でも見つかります。Contrastプロパティは、テキストの検索 (検索) とテキストの読み取りの両方に使用できます。- Contrast Color:
Contrastがオンの場合、コントラストカラーはSUTディスプレイの主要色と見なされ、他のすべての色は二次色として扱われます。背景色の見つけ方については、背景色の特定を参照してください。 - Contrast Tolerance:
Contrastがオンの場合、contrastToleranceは、ピクセルがコントラストカラーと見なされるための最大チャネル色差を設定します。
- Contrast Color:
Findタブ
パネルの右上の四分の一にはFindとReadの二つのタブがあります。これは、OCRが特定のテキスト文字列を見つけるために、またはSUT画面から未知のテキストを読み取るために使用できるからです。一部のプロパティはテキストを読むために、またはテキストを検索するためにのみ利用可能であり、両方ではありません。Findタブには、特定のテキスト文字列を検索する際に設定できる以下のプロパティが表示されます。読むと探すの違いについての詳細は、OCRの使い方を参照してください。
Case Sensitive: Eggplant Functionalがテキスト検索で大文字と小文字を区別するかどうか。このプロパティを有効にすると、テキスト検索が大文字と小文字を尊重し、テキスト文字列の大文字小文字表記に完全に一致するテキストのみを見つけるようになります。このプロパティはテキストの検索に用いられ、テキストの読み取りには用いられません。
Ignore Spaces: ignoreSpacesプロパティは、OCRテキスト検索がテキスト文字列内のスペースを無視するようにします。たとえば、文字列"My Computer"は"MyComputer"または"M y C o m p u t e r"と一致します。ignoreSpacesプロパティはデフォルトでオンになっています。これは、OCRが意図しないスペースを読み取ることがあるためです。特に、離散的な単語でない文字列や、通常と異なる字間隔のテキストでは特にそうです。
Ignore Underscores: ignoreUnderscoresプロパティは、OCRテキスト検索が検索中にアンダースコアをスペースとして扱うようにします。たとえば、文字列"My_Computer"は"My_Computer"または"My Computer"と一致します。ignoreUnderscoresプロパティはデフォルトでオンになっています。これは、OCRがアンダースコアを認識しないことがあるためです。
Ignore Newlines: 有効にすると、ignoreNewlinesはOCRテキスト検索が行の改行を無視するようにします。そのため、検索は複数の行にまたがる文字列でも一致します。このプロパティはテキスト検索にのみ使用可能です(ReadTextとは使用不可)。
Text Difference: このプロパティは、テキスト検索が指定した文字数で検索から異なるテキストを見つけるようにします。OCR検索でのみ使用可能です。
Readタブ
パネルの右上の四分割のうち��の1つには、FindとReadの2つのタブがあります。これは、OCRを用いて特定のテキスト文字列を検索するか、SUT画面から未知のテキストを読み取るかのどちらかで使用できるためです。一部のプロパティはテキストの読み取りまたは検索にのみ使用でき、両方には使用できません。Readタブには、テスト対象システム(SUT)の画面からテキストを読み取る際に設定できるプロパティが表示されます。テキストの読み取りと検索の違いについて詳しくは、OCRの使い方を参照してください。
Trim Whitespace: TrimWhitespaceがオンの場合、返されるテキストの先頭と最後からすべての空白文字が削除されます。TrimWhitespaceがオフの場合、ReadText関数は空白文字で始まるか終わるテキストを返すことができます。テキストの読み取りにのみ使用でき、事前に定義された文字列の検索には使用できません。
Multi-Line: このプロパティは、矩形内のテキストを読み取るのではなく、点近くのテキストを読み取る場合にのみ適用されます。MultiLineがオンの場合、ReadText関数は、指定した点に関連するテキスト行と、同じテキストブロックに属すると思われるその点の上下のテキスト行を返します。MultiLineがオフの場合、ReadText関数は指定した点に関連するテキスト行のみを返します。
言語認識
OCR検索に対して多くの変更を加えることができます。OCRはデフォルトでは言語辞書を使用しませんが、辞書を指定したり変更したりすることができます。また、カスタムOCR辞書を作成することもできます。このセクションのすべての OCRプロパティは、予め定義されたOCR言語の中からLanguageプロパティを設定する、有効とする単語と文字を指定する(それ以外の全ての一致を除外する)、一致可能性のある特定の単語を禁止する、またはパターンを使って作業する、など、言語に関連して動作します。
Valid Wordsドロップダウンメニュー:
このドロップダウンメニューは、相互に排他的な5つの異なるプロパティを一覧表示します。一度に設定できるのは1つだけで、そのプロパティに提供する値はこのメニューの右側のテキストフィールドに入力します。
- Valid Words: OCRが一致と見なす単語を制限することで、OCRエンジンを成功する一致に向けたり、テキスト文字列を正しく認識させることができます。アスタリスク(*)をワイルドカードとして使用して、OCRエンジンが元のテキスト文字列内の単語だけを検索するようにすることができます。このプロパティは、OCRテキストエンジンが見つけることができる単語を制限します。詳しくは、OCRエンジン辞書のカスタマイズをご覧ください。
validWordsプロパティはLanguageプロパティを上書きします。この上書きは、validWordsプロパティの一部ではない単語は返されないことを意味します。 - Preferred Words: このプロパティを現在の言語の組み込み辞書を補完する単語のリストに設定します。
PreferredWordsは、テキストの読み取りや検索のどちらにも使用できます。このプロパティはOCR辞書を変更します。詳細については、OCR辞書のカスタマイズをご覧ください。 - Valid Pattern: このプロパティは正規表現の値を取り、指定されたパターンと一致する文字や単語のみを返します。SenseTalkで使用できる正規表現の文字については、SenseTalkでのパターン使用をご覧ください。パターンを優先するが必須ではない場合は、 PreferredPattern をご覧ください。
- Preferred Pattern: このプロパティが有効にされ、正規表現の文字列が与えられると、OCRは提供されたパターンと一致するテキストを優先します。SenseTalkで使用できる正規表現の文字については、SenseTalkでのパターン使用をご覧ください。OCRにパターンマッチを必須とさせたい場合は、ValidPattern を使用してください。
- Extra Words: このプロパティを現在の言語の組み込み辞書を補完する単語のリストに設定します。これらの単語は他の辞書の単語と同様に優先されます。
Valid Characters: validCharactersプロパティは、OCRテキストエンジンが見つけることができる文字を制限します。ValidCharactersは、検索対象の文字列内の文字に限定することができます。これは、認識されていない文字からテキストの一致を「強制」しようとするときに便利です。OCRが定義されたエリアに文字が存在するが、validCharacters文字列に提供された文字と一致しない場合、"^"を返します。
Prohibited Words: OCRが認識でき、しかし探しているものではない単語を提供して、それを正しい方向に導きます。ProhibitedWordsは、テキストの読み取りと検索の両方に使用できます。このプロパティはOCR辞書を変更します。詳細については、OCR辞書のカスタマイズをご覧ください。
Language: 検索するテキストの自然言語。 (サポートされている言語のリストについては、OCR言語サポートを参照してください。)OCRはこれをガイドとして、使用している辞書で指定された単語を優先します。複数の言語を指定することができます。Eggplant Functionalはデフォルトで多数の言語を提供しており、追加の言語も購入可能です。言語が指定されていない場合でも、OCRはテキストを読むことができますが、見つけた結果を比較する辞書はありません。また、カスタムOCR辞書を作成することも可能です。
Prefer Dictionary Words: OCRは常にLanguageプロパティによって提供される辞書の単語を優先しますが、PreferDictionaryWordsはこれをさらに進め、可能な場合はOCRに辞書の単語を返すことを要求します。可能なバリアントが見つからない場合のみ、各文字の最良の解釈を使用して非辞書の単語を返します。このプロパティはOCR辞書を変更します。詳細については、OCR辞書のカスタマイズをご覧ください。テキストの読み取りと検索の両方に利用可能です。
その他のセクション
これらのOCRプロパティはあまり使われませんが、適切なシナリオでは役立つことがあります。
Aggressive Text Extraction: 画像から可能な限り多くのテキストを抽出したい場合は、このプロパティを有効にします。
Enhance Local Contrast: OCRにテキスト画像のローカルコントラストを自動的に高めてOCRエンジンに送信するようにしたい場合は、このプロパティを有効にします。このプロパティは、読まれているテキストの一部または全部が比較的低コントラストである場合、たとえば暗い背景に青いテキストの場合など、認識を助ける可能性があります。Contrastがオンになっているとき、このプロパティは効果がないため、Contrastがオフになっているときにのみ役立ちます。
Low Resolution Mode: OCRエンジンがEggplant Functionalから受け取る画像を低解像度として処理するモード(画像は実際には低解像度に変換されません)。これはOCRが小さな文字を認識するのに役立つかもしれません。
Invert Image: OCRがテキスト画像の色を反転させる(写真ネガティブのように)ことを可能にするためにこのプロパティを有効にします。OCRエンジンが処理する前に。
DPI: DPIプロパティは、SUTディスプレイのDPI(ドット/インチ)を指します。SUT上のテキストを見つけるのに問題がある場合は、SUTのDPI設定を確認し、DPIプロパティをそれに応じて調整します。
Text Rotation: このプロパティが設定されていると、OCRは定義済みの値で指定された回転度数で単語を識別します:Clockwiseは右に90度回転します。Counter-clockwiseは左に90度回転します。Upside-downは180度回転します。Noneはテキストを回転させません。テキストの読み取りと検索の両方に使用できます。
テキスト認識エリア
このエリアは、ビューアウィンドウ上の現在のキャプチャエリアで読み取られているテキストを、パネルの上部エリアで指定した設定を使用して表示します。これはライブ更新です。
3 プロパティ設定の保存またはコピー
テキストに対して機能するOCRプロパティのセットが見つかったら、現在選択している設定を新しい テキストスタイルとして保存するか(後で簡単に再使用できるように)、既存のテキストスタイルを上書きするか、またはSenseTalkコードと共に行内で使用できるプロパティリストとしてプロパティをコピーすることができます。
Copy the Property List Code: コピーアイコンをクリックして、その設定のプロパティリストをSenseTalkスクリプトに貼り付けるためにコピーします。このプロパティリストには、コピー時点でのパネル(四つのセクション:Contrast、Find/Read、Language Recognition、およびOther)で定義されているすべての現在の設定が含まれます。
Save a Text Style:
現在のテキストスタイル(パネルの上部のText Styleドロップダウンメニューに表示)を上書きするには、Save Styleをクリックします。
保存したい変更を加えた後、保存する前に上部のドロップダウンメニューを使用してテキストスタイルを変更すると、変更は選択したスタイルに置き換えられます。
新しいテキストスタイルを作成するには、Text Styleドロップダウンメニューで表示されるテキストを選択し、新しいスタイルの名前に置き換えます。その後、Save Styleをクリックします。