光学文字認識との作業
テスト中のシステム(SUT)でテキストを探す必要があり、テキストの画像をキャプチャすることが実際的ではない場合、Eggplant FunctionalやSenseTalkの光学文字認識(OCR)機能を頼りにすることができます。OCRは、動的なテキストを検索する場合に最も役立ちますが、他にも多くの実用的な用途が見つかるかもしれません。
このページで説明されているOCRの概念、およびOCRで使用されるテキストプロパティを理解するために時間をかけることを強くお勧めします。これにより、OCR検索に適切な調整を行い、テスト環境でより良い検索結果を得ることができます。
OCRで成功するために:最も一般的なOCRプロパティの使用
SenseTalkには、状況や環境に合わせてOCR検索をカスタマイズできるテキストプロパティがいくつか含まれています。カスタマイズされたOCR検索を使用すると、検索の信頼性が向上し、最良の結果を得ることができます。OCRプロパティの完全なリスト、およびテキストの読み取りとテキストの検索にどのプロパティを使用できるかについての情報については、テキストプロパティを参照してください。
OCR検索をカスタマイズするためにプロパティを使用する場合、使用するプロパティとその数を慎重に考えることが重要です。検索が機能しない場合、プロパティを追加し続けることは魅力的に思えますが、それが常に最善の方法ではありません。時にはプロパティを削除する必要があります。まず個々のプロパティを試し、必要に応じてプロパティを追加します。OCRチューナーを使用してプロパティを試し、何が機能するかを確認します。OCR検索のトラブルシューティングについての詳細は、OCRのトラブルシューティングを参照してください。
以下の各方法は、OCRの認識を改善したり、検索を高速化したりするために使用されるかもしれません。詳細については、OCR検索の速度を向上させるを参照してください。
Search Rectangles
ほぼ常に、検索矩形を追加することは有用で、OCRが検索する画面の一部を制限します。OCRが全画面を検索すると、それは遅くなるだけでなく、余分な可能性のある一致が出たり、全く一致しない可能性があるため、正確性も低下します。
検索矩形は通常、画像を使用して定義されますが、座標もこのプロパティに渡すことができます。キャプチャした画像のホットスポットが使用されるポイントを定義します(このポイントを移動する方法については、ホットスポットの使用を参照してください)。
画像を使用することは理想的です。なぜなら、SUTスクリーン上の要素が異なる場所に表示されるときに、矩��形の位置を動的にすることができるからです。例えば、テキストが常にSUTスクリーンの同じ位置に表示されないウィンドウに表示されるかもしれません。そのウィンドウにアイコンがあるかもしれません。そのアイコンの画像をキャプチャし、それを画像定義の検索矩形のアンカーとして使用することができます。
画像を使用して検索矩形を設定することができない場合は、画面座標を使用することができます。ビューワーウィンドウのCursor Locationツールバーアイコンは、この作業に役立ちます。なぜなら、それはSUT上のマウスの現在位置を示しているからです。ビューワーウィンドウのツールバーをカスタマイズする方法については、Customize the Toolbarを参照してください。
例:ウェブサイトから動的なテキストを読み取る
Google Financeページに移動し、特定の会社を検索し、その後株価を読み取るテストがあるかもしれません。OCRが価格の値を確実に、そして他の何ものでもなく読み取るために、画像を使用して検索矩形を定義することができます。使用されるコードは次のようにシンプルになります:
Log ReadText ("TLImage","BRImage")
上記のコードを動作させるためには、2つの画像をキャプチャする必要があります。この例では、画像TLImageとBRImageを使用して、検索矩形の左上と右下の角を定義しました。これらの画像をキャプチャするために、OCRが読み取るテキストに対して安定した画面の要素を1つ以上選択します。
この例では、画面の単一の要素である「会社」ラベルを使用しています。
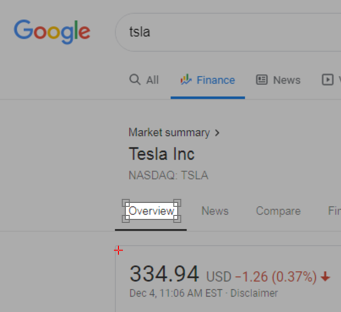
TLImageは、「会社」ラベルの画像で、ホットスポットが株価が表示されるエリアの左上の角に移動されています。
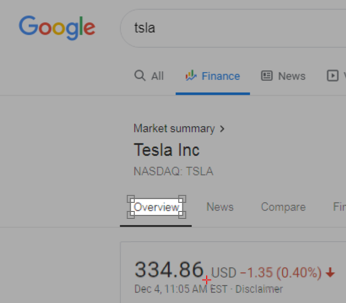
キャプチャエリアを移動せずに、ホットスポットを株価が表示されるエリアの右下の角に移動してBRImageをキャプチャします。
画像�をキャプチャし、SenseTalkコードを書いた後、上記の例はGoogle Financeの任意の会社の株価を正常に読み取ることができます。
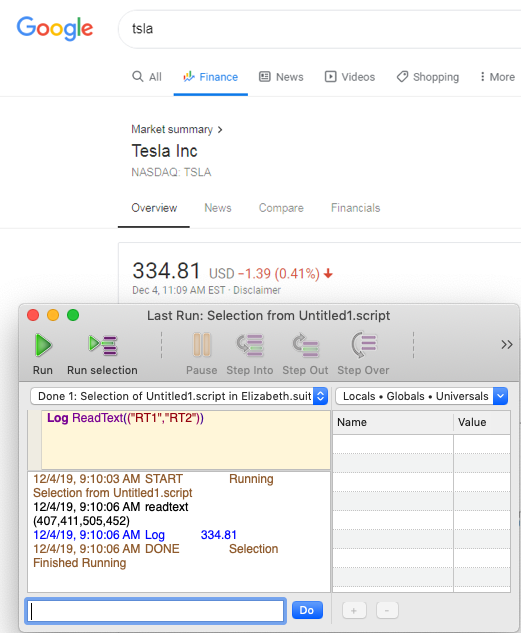 "TLImage"と"BRImage"は、OCRを使用した成功したReadText()検索のための検索矩形を設定するために使用されます。
"TLImage"と"BRImage"は、OCRを使用した成功したReadText()検索のための検索矩形を設定するために使用されます。
コントラスト
このプロパティは、Eggplant Functionalが黒と白のみを視覚するようにします。 ContrastColor(背景色)として使用されている色は白になり、それ以外のすべてのものは黒になります。白地に黒文字の場合、コードは次のようになります:
Click (Text: "hello", Contrast:On, ContrastColor: White, ValidCharacters: "hello", Searchrectangle: ("UpperLeftImage", "LowerRightImage"))
この状況では、白に近い各ピクセル(標準許容範囲の45以内)が白に変わり、それ以外のすべてが黒として読み取られます。これはOCRがテキストをより明瞭に読み取るのに役立ちます。
実際に見えるのは、アンチエイリアシングの影響を受けないこの画像です。
![]() コントラストオン時のOCRが見るもの
コントラストオン時のOCRが見るもの
Contrast設定を使用してOCRエンジンに送られるテキスト画像を確認するには、OCR Tunerパネルを使用します。このパネルには、コントラスト関連の設定の任意の組み合わせ(EnhanceLocalContrastを除く)で、OCRエンジンに認識のために送られるものを表示するライブディスプレイがあります。
灰色の背景(または中程度の値の別の色)のテキストを探す場合、少し複雑になることがあります。 ContrastToleranceを少し低く設定する(20程度まで)と、OCRが白に変えようとするピクセルの数が減ります。上の画像では、"hello"の"h"と"e"の間のピクセルが黒に変わり、2つの文字が連結しています。この状況では、OCRはまだ文字を読むことができましたが、他の状況では、これがOCRが文字を処理するのをより難しくする可能性があります。これが、スクリプト全体を実行する前に試してみることが常に良い考えである理由です。
Click (Text:"hello", Contrast:On, ContrastColor: White, ContrastTolerance: 20)
Contrast検索でContrastColorが設定されていない場合、デフォルトでは検索領域の左上隅のピクセルの色になります。
背景色の決定
背景/コントラストの色がわからない場合、任意のプラットフォーム上の特定の位置の背景色のRGB値を見つけるための2つの方法があります。
方法1:カラーピッカー(Mac)を使用する
カラーピッカーを使用するには、以下の手順を実行します:
-
リモート画面ウィンドウのツールバーのFind Textアイコンをクリックします。これでテキスト検索パネルが開きます。
-
テキストまたは背景色のボックスをクリックします。Colorsシステムパネルが表示されます。
-
カラーピッカーのアイドロッパーアイコンをクリックし、テキストまたは背景の上にカーソルを移動し、コントラスト色の設定に使用したい色を選択します。アンチエイリアシングのピクセルを選択しないように注意してください。
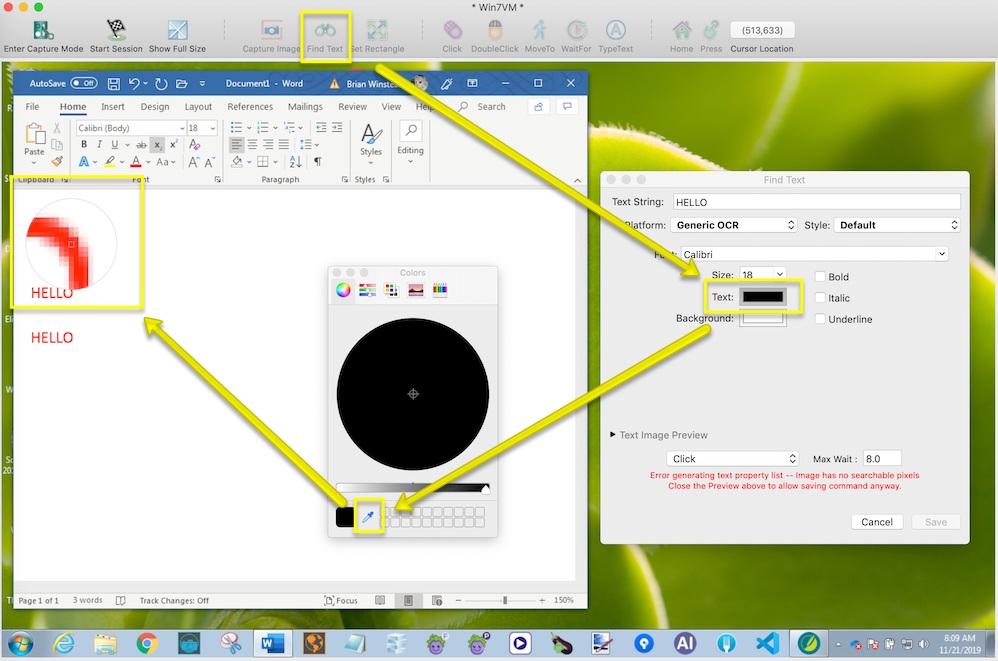 カラーピッカーを使用してMacでコントラストカラーを見つける
カラーピッカーを使用してMacでコントラストカラーを見つける
方法2: ColorAtLocation()関数を使用する
ColoratLocation() functionを使用するには、以下の手順を実行します:
- ライブモードでビューアウィンドウを開きます。Cursor Locationツールバーアイコンがすでにツールバーにない場合は、ツールバーのカスタマイズを参照してください。
- 次に、
ColorAtLocation関数を使用します。 - RGBカラー値が必要な背景上にマウスを移動します。
- SUT上のマウスの座標を使用して、Cursor Locationツールバーボタンのフィールドに表示される、このコードラインを実行ウィンドウの下部にあるアドホックdoボックス(AHDB)またはスクリプトから実行します:
put colorAtLocation(x,y) // where (x,y) refers to the coordinates found in the remote screen window
このコードラインを実行すると、指定した位置の色のRGB値が返されます。
ローカルコントラストの強調
OCRエンジンに送信されるテキスト画像のローカルコントラストを自動的に上げたい場合は、このプロパティを有効にします。このプロパティは、読まれているテキストの一部または全部が比較的低いコントラストを持っている場合、たとえば暗い背景上の青色のテキストなど、認識を助ける可能性があります。コントラストがオンになっていると、このプロパティは効果がないため、コントラストがオフの場合にのみ有用です。
Log ReadText(("TLImage","BRImage"), enhanceLocalContrast: On)
ValidCharactersおよびValidWords
ValidCharactersとValidWordsプロパティは、OCRが返す内容を制限します。これには、一致と見なす内容、テキストを読み取るときに返す内容が含まれます。
これらのプロパティに渡す値はOCRに優先されます。本質的に、OCRが何を探しているのかヒントを与えています。たとえば、ValidWords:"cat"を設定し、SUTスクリーンに"oat"という単語が表示されると、OCRはそれを"cat"と読むことがあります。
ValidCharacters
ValidCharactersプロパティは、OCRにどのグリフを探し、どのグリフを無視するかを伝えます。たとえば、OCRが文字“O”を数字“0”と誤読したり、その逆をしたりするのを防ぐために使用できます。これは、スクリプトの最適な制御のために手動で行うことができます。または、アスタリスク(*)を使用して自動的にvalidCharactersを検索対象のテキストに設定することができます。
ValidCharactersは、テキストを事前に知らない状況でテキストを読むときや、文字セットを制限する必要があるときに最も役立ちます。たとえば、お金を扱うときに数字と文字を区別するのに使用できます。
例
//ValidCharacters を手動で設定する:
Log ReadText[("TLImage","BRImage"], ValidCharacters:"$£€.,0123456789") -- 通貨記号を含む数値を読み取る
//変数と一緒にValidCharactersを使用する:
Put "Charlie" into MyText
Click (Text: MyText, ValidCharacters: MyText)
//アスタリスクを使用してValidCharactersを検索対象のテキストに設定する:
Click (Text:"CoDe13v9065", ValidCharacters:"*", SearchRectangle:("UpperLeftImage","LowerRightImage"))
ValidWords
ValidWordsプロパティはValidCharactersに似ていますが、有効とされる文字だけでなく、それらの文字の配置も強制します。これがValidWordsが特定のフレーズを検索するときによく使用される理由です。
ValidWordsは、ValidWordsに提供された単語のみを含む新しい言語ライブラリを基本的に作成するため、設定されたLanguageプロパティをオーバーライドします。
例:
Put "Charlie Brown" into mytext
Click (text: mytext, searchRectangle:("RT1","RT2"), validwords:mytext)
OCRに無視することを伝える
OCRの使用はすべて、テキスト検索に適切なプロパティをOCRに提供することに関連しています。 これらのプロパティのほとんどは、OCRが何を認識するべきかに向けるのが一般的ですが、場合によっては、誤った結果から逃れるために何を認識しないかを伝えることでそれを逸らす方が良いです。 以下のプロパティは、テキストを扱うときにOCRが無視するべきものを具体的に伝えます。
Ignore Spaces
テキスト検索のプロパティとして、IgnoreSpacesはその名の通り、検索内のスペースを無視するために使用できます。 たとえば、このアプローチは、文字間のス�ペースが一貫していないシナリオで役立つ可能性があります。 OCRは、存在しない場所にスペースがあると見ることがありますし、存在する場所のスペースを無視することがあります。 IgnoreSpacesプロパティをONに設定すると、OCRは"flowerpot"を"flower pot"と一致させ、その逆も同様です。 このプロパティを使用すると、OCRは検索している文字列と見つけた文字列の両方からスペースを取り除き、一致を見つけます。
Click (Text:"flower pot", validCharacters:"*", ignoreSpaces:ON, searchRectangle:("UpperLeftImage","LowerRightImage"))
Ignore Underscores�
ignoreUnderscoresプロパティにより、OCRテキスト検索はアンダースコアをスペースとして扱います。 たとえば、文字列"My_Computer"は"My_Computer"または"My Computer"と一致します。 OCRエンジンがアンダースコアを認識できないことがあるため、ignoreUnderscoresプロパティはデフォルトでオンになっています。
Click (Text:"My_Computer", validCharacters:"*", ignoreUnderscores:ON, searchRectangle:("UpperLeftImage","LowerRightImage"))
改行無視
改行は、ラインブレイクを作成するリターンキャラクターの一種です。 有効にすると、ignoreNewlinesはOCRテキスト検索がラインブレイクを無視するようにし、したがって検索は複数の行にまたがって壊れている文字列でも一致します。 このプロパティはテキスト検索にのみ利用可能であり、ReadTextでは利用できません。
Click(Text:"Constantine Papadopoulos",IgnoreNewlines:On)-- このように長い名前の場合、テスト対象のアプリケーションのインターフェースで2行目に折り返す可能性がありますが、OCRはIngoreNewlinesを有効にするとそれを読むことができます。
CaseSensitive
CaseSensitiveプロパティは、OCRがテキストを認識するときにケースを考慮す�るかどうかを決定します。 OCRを使用して検索しているテキスト文字列の大文字小文字を検証したい場合、このプロパティを有効にしてテキスト検索がケースを尊重し、検索文字列の大文字小文字の正確な一致のみを見つけるように強制します。 このプロパティは検索専用で、ReadTextでは使用できません。
例:
Put "COUPON13995a" into Coupon
MoveTo(Text:Coupon,CaseSensitive:Yes)
ValidPattern
このプロパティは、正規表現の値を取り、指定されたパターンと一致する文字または単語のみを返します。 SenseTalkで使用できる正規表現文字については、Using Patterns in SenseTalkを参照してください。 パターンを好むが必要としない場合は、PreferredPatternを参照してください。
パターンを使用したい場合は数多くあります。 1つの例は、SUT上の日付から時間を検索したり読み取ったりするときです。
例
Log ReadText(("RT1","RT2"), validPattern:"[0-9][0-9]:[0-9][0-9]") -- SUT画面から時間を読み取ります。
put formattedTime("[m]/[d]/[year]") into today -- formats today's date according to the pattern provided to formattedTime()
Click (Text:Today, SearchRectangle:("TL_Date","BR_Date"), validPattern:"[0-9]/[0-9]/[0-9][0-9][0-9][0-9]") -- SUT画面に存在する日付をクリックして、日付と時間のパネルを開きます。この例でvalidPatternに渡されるパターンで読み取られる日付形式は1/4/2020になります。
言語指定
Languageを使用すると、指定された言語または複数の言語のテキストを検索でき�ます。言語を指定する必要はありません。しかし、言語を設定すると、OCRにガイドを提供します。なぜなら、それは提供された辞書または辞書で指定された単語を優先するからです。
Eggplant Functionalにはデフォルトで多数の言語が利用可能で、追加の言語を購入することもできます。サポートされている言語のリストについては、OCR Language Support.をご覧ください。また、現在の辞書を上書きまたは変更するプロパティを使用して、カスタムOCR辞書を作成することもできます。
例
同じ文に異なる言語の文字が含まれている場合、複数の言語を指定できます。
SUTに表示されるテキストの文字列:
//料理4出6「です。")
多言語の文字を読むために使用されたSenseTalkコード:
ReadText((475,179,608,212), Language:"Japanese,English")
OCRエンジン辞書のカスタマイズ
テキスト読取り関数を使用する際には、OCRエンジンが興味のあるテキストを見つけるのを助けるために、OCR辞書をカスタマイズできます。SenseTalkには、OCR辞書から単語を追加または削除するためのreadText関数呼び出しのオプションまたはテキストプロパティリストとして使用できるプロパティがいくつか含まれています:
- ExtraWords: このプロパティを現在の言語の組み込み辞書を補完する単語のリストに設定します。
- PreferDictionaryWords: このプロパティを有効にすると、OCRエンジンに、可能な限り辞書で定義された単語として各単語を読むように指示します。適切な辞書の単語が見つからない場合、エンジンは各文字の最善の解釈を使用して非辞書の単語を返します。
- PreferredWords: このプロパティを現在の言語の組み込み辞書を補完する単語のリストに設定します。
PreferredWordsはテ��キストの読取りまたは検索に使用できます。このプロパティはOCR辞書を修正します。詳細については、OCR辞書のカスタマイズをご覧ください。 - ProhibitedWords: このプロパティを認識から除外する単語のリストに設定します。エンジンがこれらの単語のように見える何かを見つけた場合、異なる単語を得るために文字の異なる解釈にフォールバックします。詳細については、ProhibitedWordsをご覧ください。
- ValidWords: このプロパティを設定して、OCRテキストエンジンが見つけることができる単語を決定します。
validWordsプロパティはLanguageプロパティを上書きします。 - **ValidPatternおよびPreferredPattern**も
Languageを置き換えますが、特定の単語の代わりにパターンを使用します。
上記のすべてのプロパティは相互排他的です。OCRコマンドのインラインにこれらのうち1つ以上を設定しないでください。
これらのプロパティは、スクリプト全体または特定のコマンドに対して設定できます:
// スクリプト全体の単語リストを設定
set the readTextSettings to (extraWords:"ean carner")
put readText(rect, PreferDictionaryWords:yes, prohibitedWords:"can carrier tap")
// 単一のコマンドに単語リストを設定
set rect to the RemoteScreenRectangle
put readText(rect, extraWords:"ean carner", PreferDictionaryWords:yes, prohibitedWords:"can carrier")
上記のコードの両方のバージョンでは、「can」と「carrier」を禁止単語として設定し、それらを辞書から実質的に削除します。また、「ean」と「carner」を新しい辞書の単語として追加します。この例では、OCRエンジンが画面上の個々の文字に対する自身の最善の解釈を無視し、見ているものから辞書の単語を作り出すために、個々の文字のあまりありそうでない解釈にフォールバックするように強制します。
ExtraWordsプロパティはカスタムOCR辞書を作成し、上記の例に示すように、コマンドごとにまたはスクリプト全体に提供することができます。また、所望の単語をリストする外部ファイルを使用して、スクリプト全体のExtraWords辞書を設定することもできます:
extraWords 辞書をスクリプト内の ReadText() の任意のインスタンスに適用します
readTextSettings を {ExtraWords:file ResourcePath("OCR-Dictionary.txt")} に設定します。
外部ファイルを使用して、個々のコマンドの単語リストを指定します。
readTextSettings を {ExtraWords:file ResourcePath("OCR-Dictionary.txt")} に設定します。
外部データファイルを使用する場合、ファイルは各単語間にセパレータがある形式でフォーマットされていなければならず、それはスペース(ホワイトスペース)文字または改行文字とすることができます。
テキストスタイルの使用
あなたのテストシナリオに適したプロパティセットを選択したら、それをテキストスタイルとして保存するオプションがあります。テキストスタイルは、Eggplant Functionalのテキスト設定、OCRチュ��ーナー、またはOCR更新パネルで定義されたテキストプロパティの保存セットです。テキストスタイルを作成するには、これらのパネルのいずれかを使用します。
各スタイルは、テスト対象のアプリケーションで繰り返し遭遇するメニューアイテムやタイトルバーなど、特定のフォントやグラフィカルユーザーインターフェース要素に通常はカスタマイズされます。テキストスタイルは、OCR検索とReadTextの両方に適用できます。読み取りと検索の違いについての詳細は、OCRの使用方法を参照してください。
OCRのトラブルシューティング
OCRは強力なツールですが、さまざまな使用方法があり、探している結果を得るためにプロパティの適切な組み合わせを見つける必要がある場合があります。OCR更新パネルとOCRチューナーを使用すると、結果が大幅に改善されます。
テキストプロパティにあるOCRプロパティの表を覚えておくと、トラブルシューティングに役立ちま��す。このページは、OCRを使って作業する際に役立つ素晴らしい参照です。
検索の失敗:OCR更新パネルとOCRチューナーの有効化
OCR検索を行ってOCRエンジンがあなたのテキスト文字列を見つけられない場合、Eggplant Functionalはあなたのスクリプトを失敗させる可能性のある例外をスローします。ただし、OCR更新パネルを有効にすると、OCR更新機能は検索に異なるプロパティを適用してマッチングを見つけられるか試みます。この機能をAuto Updateに設定すると、ユーザーの操作なしで動作します。また、Show Panelに設定すると、OCR検索が失敗した際にOCR更新パネルが開きます。この機能の使用に関する詳細な情報については、OCR更新パネルを参照してください。
OCRを使用してスクリプトの新しい部分を作成したり、動作していないOCR検索のトラブルシューティングを行っている場合、OCRチューナーはOCR更新パネルと同じプロパティ調整を提供する便利なデバッグツールです。このパネルを積極的に使用してOCRプロパティを調整し、ビューアウィンドウ上の現在のキャプチャエリアで読み取られている内容のライブ結果を確認します。必要に応じて調整を行い、後で使用するために結果を保存します。これは、生成されたテキストプロパティリストをコピーするか、テキストスタイルを保存することで行えます。この機能の使用に関する詳細な情報については、OCRチューナーの使用を参照してください。
トラブルシューティングのアプローチ
- 異なる方向から検索を試みてみてください。 OCRは与えられたテキストを検索することも、SUTの画面からテキストを読み取ることも可能です。特定のテキスト文字列を見つけるのに困っている場合は、
readText関数を使ってテキストを読み取り、何があると思われるかを教えてもらうと良いでしょう。これにより、検索を調整するための適切なプロパティを選択するのに役立つ可能性があります。Ad Hoc Do Boxはこれに役立つツールで、Eggplant Functionalの実行ウィンドウに直接組み込まれたデバッグツールです。スクリプトを変更することなく、スクリプトの実行中にコードの行を実行することができます。このツールの使用方法については、スクリプトのデバッグを参照してください。 - 検索範囲を調整してみてください。 矩形が設定されていると仮定すると、その位置、サイズ、読み取ろうとしているテキストからの近さや遠さを変更してみてください。もし
ReadTextを矩形ではなく点で使用しているなら、その点の位置を調整してみてください。また、読み取る範囲をより明確に定義するために、矩形を使用することも試みてみてください。 - OCRチューナーを使用してみてください。 OCRチューナー��は、OCRの作業に特化したEggplant Functional内蔵の診断ツールです。OCRテキスト認識と共に使用されるプロパティを調整して検索結果を改善する際、少ない方が良いと言えます。プロパティを積み重ねる前に、個別に試してみるか、より小さい組み合わせで試すことで、最良の結果を得ることができます。このツールの使用方法については、OCRチューナーの使用を参照してください。
- コントラスト設定を調整してみてください。 これには、
contrastColorが含まれます。OCRチューナーは、コントラスト色を調整し、与えられたコントラストプロパティでOCRが何を見ているかをリアルタイムで表示される更新を確認できる良い場所です。OCRが何を見ているかを知ることで、問題を解決するための準備が整います。 - 言語関連のプロパティを設定してください。 言語プロパティには
ValidCharactersやValidWordsが含まれ、これらはOCRが指定された単語や文字だけを認識するように強制します。例えば、readText関数が「hello」を返すのに対し、目指しているテキストは実際には「hell0」というパスワードであるということが分かった場合、validCharacters:"hell0"を指定すると結果が改善するかもしれません。実際の言語辞書の指定やパターンの利用も有用です。
- コントラスト設定を調整してみてください。 これには、
- 使用しているプロパティが行っている検索のタイプに適していることを確認してください。 SUTからテキストを読み取ることと、既知のテキスト文字列を検索することは異なり、一部のプロパティは一方にのみ適用します。すべてのOCRプロパティとそれらが使用できるものについての完全なリストについては、OCRテキストプロパティ参照表をご覧ください。
- 新しく始めてみてください。 いくつかの異なるプロパティを試してみたが、まだうまくいっていないものを見つけることができていない、またはプロパティなしで検索を試行していない場合、現在使用しているすべてのプロパティを削除し、新しく始めることを考えてみてもいいかもしれません。まずはプロパティを設定せずに検索を実行し、次に一つや二つのプロパティを試してみてください。テストシナリオに最も適している組み合わせを見つけるために、異なる組み合わせをテストしてみてください。
よくある問題シナリオ
- 同じテキストの複数のインスタンス。 SUT画面上に同じテキストが複数存在し、特定のものと対話する必要がある場合は、検索矩形を設定してみてください。同じ画像がSUT上に複数存在する場合の対応策は、このシナリオでも使用できます。詳細については、同一画像の複数インスタンスの取り扱いを参照してください。
- スペースの読み取りや検出が困難。 OCRは時折、スペースを正確に検出するのが難しいことがあります。スペースを含むテキストを扱っていて、OCRがそれを正確に読み取ったり検出したりしていない場合、ただしテストの目的でスペースを確認する必要がない場合は、IgnoreSpacesやIgnoreUnderscoresを試してみてください。これらのプロパティのどちらかがあなたのシナリオで機能しない場合は、以下の代替手段を参照してください。
代替手段
OCRは有用なツールですが、すべての状況に適しているわけではありません。時折、非常にコントラストが低い、背景が特異な、あるいは他の理由でOCRが読み取れない動的テキストの状況があります。そのような状況では、以下のオプションを検討してみてください:
- キャラクターコレクション。 特定のテキスト文字列のOCR検索を試みている場合、キャラクターコレクションの使用を検討してみてください。キャラクターコレクションは通常の画像コレクションですが、画像は個々の文字です。大量の作業に思えますが、Eggplant Functionalにはキャラクターコレクションの特殊なキャプチャモードがあります。詳細については、キャラクターコレクションの使用を参照してください。
- RemoteClipboard関数。 SenseTalkには、SUTクリップボードの内容をキャプチャして、その情報をスクリプトに戻すための
RemoteClipboard関数があります。選択可能なテキストからSUTを読み取ることを考えている場合は、テキストを選択するようにスクリプトを作成し、その情報をRemoteClipboardを使��用してスクリプトに戻すようにし、ReadTextの代わりに使用してみてください。
OCR検索の速度を向上させる
OCRテキスト検索の柔軟性はトレードオフとして存在します:OCRテキスト検索は画像検索ほど速くはありません。スクリプトができるだけ効率的に動作するように、以下のベストプラクティスに従ってください:
- 検索矩形を使用する。 検索矩形を使用して検索領域を制限すると、スクリプトの実行速度が大幅に向上します。探しているテキストの場所を絞り込むことができる場合(例えば、タスクバーや特定のウィンドウ内など)、その場所に検索を限定するために検索矩形を設定することができます。OCRが検索しなければならない領域のサイズが小さいほど、検索を実行するのにかかる時間は少なくなります。詳細については、テキスト設定や画面の一部を検索するを参照してください。
- SUT上の混乱を最小限に抑える。 不要なウィンドウを閉じる、シンプルなデスクトップ背景を使用するなど、SUTを整理することは決して損ではありません。スクリプトがOCRテキスト検索を含む場合、整理されたデスクトップは実行時間の貴重な秒数や分を節約することができます。