Using the OCR Tuner
The optical character recognition (OCR) search engine in Eggplant Functional contains many parameters that can help you improve your OCR searches.
The OCR Tuner is a debugging tool that allows you to change OCR property settings and see the results in real time, giving you the information you need to make informed decisions about which OCR properties to use in a given situation. After you make adjustments to these OCR properties, you can save the set as a template style and re-use the same settings again later. For more on text styles, see Text Preferences.
It is a good idea to familiarize yourself with the various properties that can be used with OCR. Text Properties is a great reference guide, as well as Working with OCR.
The view of the OCR text properties provided by the OCR Tuner is also visible in Text Preferences and the OCR Update Panel.
1. Launch the OCR Tuner Panel
-
Set the capture area around the text you want to tune OCR to find.
-
Open the OCR Tuner. The OCR Tuner can be opened from the Viewer Window when it is in capture mode. Either right-click on the SUT screen when the Viewer window is in capture mode, click the drop-down arrow located at the upper-right corner of the Capture Area, or click the OCR Tuner button in the toolbar (the toolbar must be customized for this to show).
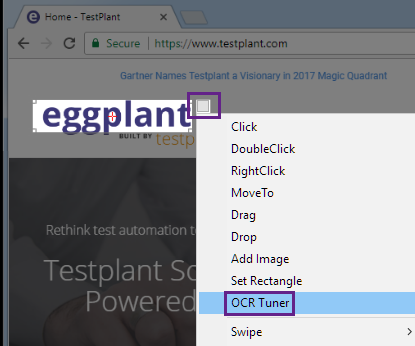
-
The OCR Tuner panel appears.
2. Adjust the OCR Properties
This panel is built for trial and error, so change and adjust the properties as needed to obtain your desired results.
Apply one property at a time to your search and look at the results to see how each property impacts the outcome individually. Then, try combining properties that are helpful in your scenario to see how they interact. Piling on numerous property settings at once makes it tricky to figure out which ones are actually helping to achieve the results you want. For more information, see Troubleshooting OCR.
Each section on this panel is outlined below. For detailed information on each of the individual text property options on this panel, see Text Properties.
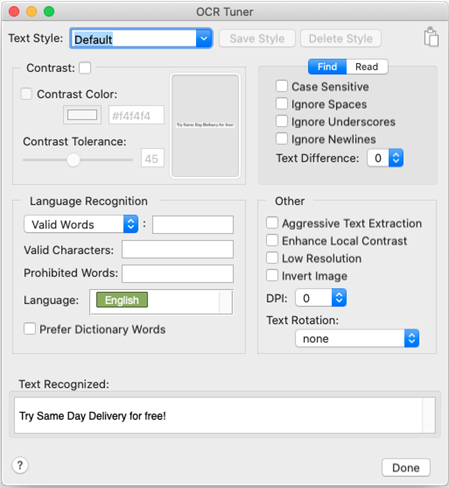
Text Style
A text style is a saved set of text properties as defined in the Eggplant Functional Text Preferences, OCR Tuner, or OCR Update panel. Each text style is typically tailored to a particular font or type of GUI element, such as a menu item or title bar that will be encountered repeatedly in an application under test. Text styles can be applied to both OCR searches and ReadText(). For more on the difference between reading and searching, see How to Use OCR.
The panel opens with the Default style selected. Once you modify the OCR Properties in the sections below this one, you have altered the current style. To save this new style, select the word "Default" in the Text Style drop-down menu and change the name, or select the style you want to override (the Default style can be modified). Click Save Style.
To delete the current selected style, click Delete Style. This option is disabled when the Default style is selected.
To the right of this section is the copy icon. This can be used to copy the current text properties as you have them set in the following sections for use in your script. For more on this see Save or Copy Property Settings.
Contrast Section
The Contrast section allows you to set and work with the Contrast property and related properties. The Contrast setting converts the image OCR takes of the system under test (SUT) to black and white before sending it to the OCR engine for recognition. This interactive section has a live-update area to the right that shows the current search rectangle as it is drawn in your Viewer window, and how it will be sent to the OCR engine with the current Contrast settings.
-
Contrast: {#contrast}Whether or not the SUT display is converted to a high contrast two-color image before it is sent to OCR for analysis. If
contrastis on, a color referred to as the "contrast color" (which can be set using theContrastColorproperty) is considered the primary color of the SUT display, and all other colors are treated as the secondary color. Text can be found in either color. TheContrastproperty is available for use with both searching for (finding) text and reading text.- Contrast Color: If
Contrastis on, the contrast color is considered the primary color of the SUT display, and all other colors are treated as the secondary color. For instructions on finding the background color, see Determining the Background Color. - Contrast Tolerance: When
Contrastis on,contrastTolerancesets the maximum per-channel color difference that is allowed for a pixel to be seen as the contrast color.
- Contrast Color: If
The Find Tab
The upper-right quadrant of the panel has two tabs: Find and Read. This is because OCR can be used to either find a given string of text, or read unknown text off of the SUT screen. Some properties are only available for use when reading text, or for searching text, but not both. The Find tab displays the following properties that can be set when searching for a given string of text. For more on the differences between reading and finding text, see How to Use OCR.
Case Sensitive: Whether or not Eggplant Functional considers case in text searches. Enable this property to force text searches to respect case and only find text that matches your text string’s capitalization exactly. This property is for searching for text, not reading text.
Ignore Spaces: The ignoreSpaces property causes OCR text searches to disregard spaces in your text string. For example, the string "My Computer" would match "MyComputer" or "M y C o m p u t e r". The ignoreSpaces property is on by default. This is because the OCR sometimes reads spaces that are not intended, especially in strings that are not discrete words, and in text with unusual letter-spacing.
Ignore Underscores: The ignoreUnderscores property causes OCR text searches to treat underscores as spaces during searches. For example, the string "My_Computer" would match "My_Computer" or "My Computer". The ignoreUnderscores property is on by default, because the OCR sometimes fails to recognize underscores.
Ignore Newlines: When enabled, ignoreNewlines causes OCR text searches to ignore line breaks, so a search will match a string even if it's broken over several lines. This property is only available for text searches (not available with ReadText).
Text Difference: This property causes text searches to find text that differs from your search by a given number of characters. Only available with OCR searches.
The Read Tab
The upper-right quadrant of the panel has two tabs: Find, and Read. This is because OCR can be used to either find a given string of text, or read unknown text off of the SUT screen. Some properties are only available for use when reading text, or for searching text, but not both. The Read tab displays the following properties that can be set when reading text off the screen of the system under test (SUT). For more on the differences between reading and finding text, see How to Use OCR.
Trim Whitespace: When TrimWhitespace is on, all whitespace characters are removed from the beginning and end of returned text. When TrimWhitespace is off, the ReadText function can return text that starts or ends with whitespace characters. Only for use with reading text, not searching for pre-defined strings.
Multi-Line: This property only applies when reading text near a point, as opposed to reading text within a rectangle. When MultiLine is on, the ReadText function returns the line of text associated with your point, and any lines of text above and below that point if they appear to belong to the same block of text. When MultiLine is off, the ReadText function only returns the line of text associated with the point.
Language Recognition
There are many modifications you can make to an OCR search by working with language settings. OCR does not use a language dictionary by default, but a dictionary can be specified or modified, and you can also create a Custom OCR Dictionary. All of the OCR Properties in this section work with language, whether that is setting the Language property using one of the predefined OCR Languages, telling it what words and characters it should consider valid (eliminating all other matches), prohibiting certain words that may come up in matches, or working with patterns.
The Valid Words drop-down menu
This drop-down menu lists five different properties you can set, which are mutually exclusive. Only one can be set at a time, and the value you provide to that property goes in the text field to the right of this menu.
- Valid Words: Limiting the words that OCR can consider a match allows you to steer the OCR engine toward a successful match, or force the engine to recognize your text string correctly. You can use the asterisk (*) as a wildcard so that the OCR engine looks only for the words in your original text string. This property limits the words that may be found by the OCR text engine; for more see Customize the OCR Engine Dictionary. The
validWordsproperty overrides theLanguageproperty. This override means that words that are not part of thevalidWordsproperty are not returned. - Preferred Words: Set this property to a list of words to supplement the built-in dictionary for the current language.
PreferredWordscan be used for either reading or searching for text. This property modifies the OCR dictionary. For more information, see Customize the OCR Dictionary. - Valid Pattern: This property takes a regular expression value and returns only characters or words that match the pattern specified. For information on regular expression characters that can be used with SenseTalk, see Using Patterns in SenseTalk. If you want OCR to prefer a pattern but not require it, see PreferredPattern.
- Preferred Pattern: When this property is enabled and given a regular expression string, OCR gives preference to text that matches the provided pattern. For information on regular expression characters that can be used with SenseTalk, see Using Patterns in SenseTalk. If you want the OCR to require a pattern match, use ValidPattern.
- Extra Words: Set this property to a list of words to supplement the built-in dictionary for the current language. These words will be given preference the same way as other dictionary words.
Valid Characters: The validCharacters property limits the characters that may be found by the OCR text engine. ValidCharacters can be limited to the characters in the string you are searching for by setting the string to "*". This can be useful if you are trying to "force" a text match from characters that are not being recognized. If OCR determines that characters are present in the defined area but they do not match characters provided in the validCharacters string, it will return "^".
Prohibited Words: Provide words OCR can recognize that are not what you are looking for to help steer it in the right direction. ProhibitedWords can be used for both reading and searching for text. This property modifies the OCR dictionary. For more information see Customize the OCR Dictionary.
Language: The natural language of the text you are searching for. (For a list of supported languages, see OCR Language Support.) OCR uses this as a guide, giving preference to words specified in the dictionary it is using. More than one language can be specified. Eggplant Functional comes with numerous languages by default, and additional languages are available for purchase. If no language is specified OCR will still read text; it just won't have a dictionary to compare its findings to. You can also create a Custom OCR Dictionary.
Prefer Dictionary Words: While OCR always prefers words in any dictionary it is provided by the Language property, PreferDictionaryWords takes this a step further and requires OCR to return a dictionary word if possible. It will only return a non-dictionary word—using its best interpretation of each character—if no possible variants are found. This property modifies the OCR dictionary. For more information see Customize the OCR Dictionary. Available for both reading and searching for text.
Other Section
These OCR properties are not often used, but can be helpful in the right scenarios.
Aggressive Text Extraction: Enable this property if you want OCR to extract as much text from the image as possible.
Enhance Local Contrast: Enable this property if you want OCR to automatically increase the local contrast of the text image being sent to the OCR engine. This property may aid recognition when some or all of the text being read has relatively low contrast, such as blue text on a dark background. When Contrast is turned on, this property has no effect, so it is only useful when Contrast is turned off.
Low Resolution Mode: A mode of processing used by the OCR engine to treat the image it receives from Eggplant Functional as low resolution (the image is not actually converted to a lower resolution). This might help OCR recognize smaller characters.
Invert Image: Enable this property for OCR to invert the colors of the text image (like a photo negative) before sending it to the OCR engine for processing.
DPI: The DPI property refers to the DPI (dots per inch) of the SUT display. If you are having problems finding text on the SUT, check the SUT's DPI setting, and adjust the DPI property accordingly.
Text Rotation: When this property is set, OCR identifies words at the degree of rotation specified by one of the predefined values: Clockwise rotates 90 degrees to the right; Counter-clockwise rotates 90 degrees to the left; Upside-down rotates 180 degrees; None does not rotate the text. Can be used for both reading and searching for text.
Text Recognized Area
This area displays the text being read in the current Capture area on the Viewer window using the settings you have provided in the above areas of the panel. This is a live update.
3 Save or Copy Property Settings
Once you find a set of OCR properties that works for your text, you can either save the settings you currently have selected as a new Text Style (allowing for easy re-use later), overwrite an existing text style, or copy the properties as a property list that can be used with in line with your SenseTalk code.
Copy the Property List Code: Click the copy icon to copy a property list with those settings for pasting into a SenseTalk script. This property list will contain all the current settings as defined on the panel (in the four sections: Contrast, Find/Read, Language Recognition, and Other) at the time of copy.
Save a Text Style:
To overwrite the current text style (shown in the Text Style drop-down menu at the top of the panel), click Save Style.
If you make modifications that you want to save and then change the text style using the drop-down menu at the top before you save, your modifications will be replaced by the style you have selected.
To create a new text style, select the text shown in the Text Style drop-down menu and replace it with the name of your new style. Then click Save Style.