OCR更新パネル
OCR更新パネルは、テキスト検索が一致を見つけられなかった場合に、実行時に光学的文字認識(OCR)テキスト検索設定を調整することができます。このパネルは、テスト対象システム(SUT)での検索の診断結果を提供します。その後、OCR検索のプロパティを成功する可能性のあるものに変更し、検索を再実行し、異なる検索設定での結果を表示します。このパネルで行われる変更は、現在のテスト実行にのみ適用されます。
OCR更新パネルの有効化
OCR更新パネルでは、スクリプトの実行中に一致が見つからない場合に、テキスト検索の診断と修正を実行時に行うことができます。有効化の方法により、このパネルはスクリプトが予想しないテキストの複数のインスタンスが見つかった場合や、Auto Update機能をトリガーする場合にも表示されます。Auto Updateは、ユーザー入力なしでテキストと画像の両方で動作し、元の検索設定を使用した検索が成功しない場合に設定を調整し、一致を見つけるために使用します。これらの設定は、Auto Updateパネルを通じて画像に適用することができます。この機能についての詳細は、Auto Updateパネルの使用を参照してください。
OCR更新パネルと関連するAuto Updateパネルの機能は、Run > Image Updateメニューで表示されるオプションを調整することでメインメニューから有効化できます。Image Update panel、OCR更新パネル、およびAuto Updateパネルはすべてこのメニューを通じて制御されます。これらのメニューオプションは、スクリプトの実行中にOCR更新パネルが開いたときにも調整できます。
この機能は、Image Update panelと同じです。両方のパネルは、このメニューオプションを使用して有効化または無効化されます。
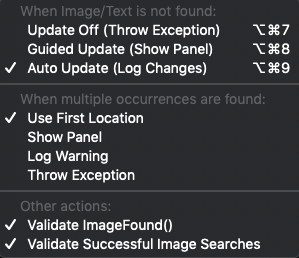 Run>Image Updateの下にあるImage Updateパネルメニュー
Run>Image Updateの下にあるImage Updateパネルメニュー
Image Updateメニューを使用してOCR更新パネル機能を調整する際の選択肢は次のとおりです。
OCR更新パネルは、**Throw Exception (Update Off)**オプションを設定すると表示されません。パネルは、**Guided Update (Show Panel)**オプションを使用して手動設定を選択したときに、実行時に表示されます。**Auto Update (Log Changes)**が選択されている場合、スクリプトの実行後にAuto Updateパネルが表示されます。
画像/テキストが見つからない場合:
-
Update Off (Throw Exception): Eggplant Functionalは例外をスローし、画像またはOCR検索が一致を返さない場合、スクリプトは失敗します。OCR更新機能は使用されません。
-
Guided Update (Show Panel): このオプションを選択すると、テキスト検索が失敗した際に実行時にOCR更新パネルを手動で操作し、適切な一致を見つけるための設定を調整することができます。この方法は直接的な人間の介入を必要とするため、立会いテスト実行に最適です。ただし、そのために最も適用される一致に対する制御を得ることができます。このメニューオプションは以前は"Show Panel (Manual Update)"と呼ばれていました。
-
Auto Update (Log Changes): これにより、Auto Update機能が活性化し、検索の失敗時に自動的に検索設定を調整して一致を見つけることができるかどうかを確認します。
Auto Updateオプションは、スクリプトの実行中にOCR更新パネルを開かないため、監視されていないスクリプトの実行に適しています。頻繁に、それは一致を見つけてスクリプトの実行を続けることができ、それ以外の場合は検索は例外をスローして失敗します。Auto Updateを使用している場合、あなたのパラメータが広すぎると、意図しない��結果で間違ったテキストに一致する可能性があることに注意してください。 これらの設定は、実行時に行われたときに恒久的に保存されません。変更を確認するには、スクリプトの実行後に表示されるAuto Updateパネルを参照してください。提案された変更を恒久的にするには、スクリプトを手動で編集する必要があります。
Auto Updateパネルの使用について詳しくは、Auto Updateパネルの使用を参照してください。
OCR更新パネルの使用
手動オプションを使用している場合、OCR更新パネルはスクリプトがOCRテキスト検索で失敗したときに自動的に開きます。パネルはいくつかのタブで構成されており、それぞれが以下で説明されています。
各タブの下部には、同じ3つのボタンがあります:
- Abort: このボタンを使用して、スクリプトの実行を中止します。
- Proceed: このボタンを使用して、スクリプトが次のステップに進むようにします。ただし、スクリプトが失敗した検索例外を処理するように書かれていない場合、このオプションを使用するとスクリプトが失敗します。
- Try Again: このオプションを使用して、例外を引き起こした検索を再試行してスクリプトに戻ります。新しい検索が成功した場合、スクリプトは実行を続けます。
各タブの左下側には、OCR更新パネルが表示される条件を変更したい場合に選択できる以下の項目があります:
Update Off: OCR更新パネルは使用されません。
Manual Update: このオプションは、OCR検索が実行時に失敗したときにOCR更新パネルを開き、設定を対話式に操作して適切な一致を見つけることができます。
Auto Update: この設定は、追加の検索パラメータを試して一致を作成し、ユーザーの操作なしにスクリプトを続行するために、OCR更新パネルを内部的に動作させます。
Auto Updateオプションを使用すると、スクリプトの実行中に行われた変更は_memory only_に適用されます。変更された設定はResultsパネルのRemedy列から見ることができますが、検索設定の変更を恒久的にするにはスクリプトを手動で編集する必要があります。
スクリプトがAuto Updateオプションをどの程度頻繁に利用しているかを追跡することは良いことです。これがどの程度頻繁に発生しているかを確認するには、以下の手順を実行します:
-
SuiteウィンドウのResultsペインで問題のスクリプトをクリックします。この操作により、現在のスイートで実行したテストの記録を表示するResultsペインが表示されます。
-
Resultsペインの上部の行をクリックします。
-
Resultsペインの下部の結果を確認し、テキストとメッセージの列でAutoUpdate文字列を探して、自動更新がどの程度の頻度で行われ、そのケースを解決するのにどれくらいの時間がかかったかを確認します。例えば、次のスクリーンショットに示すように、紫の長方形でマークされたAutoUpdate文字列を探してください:
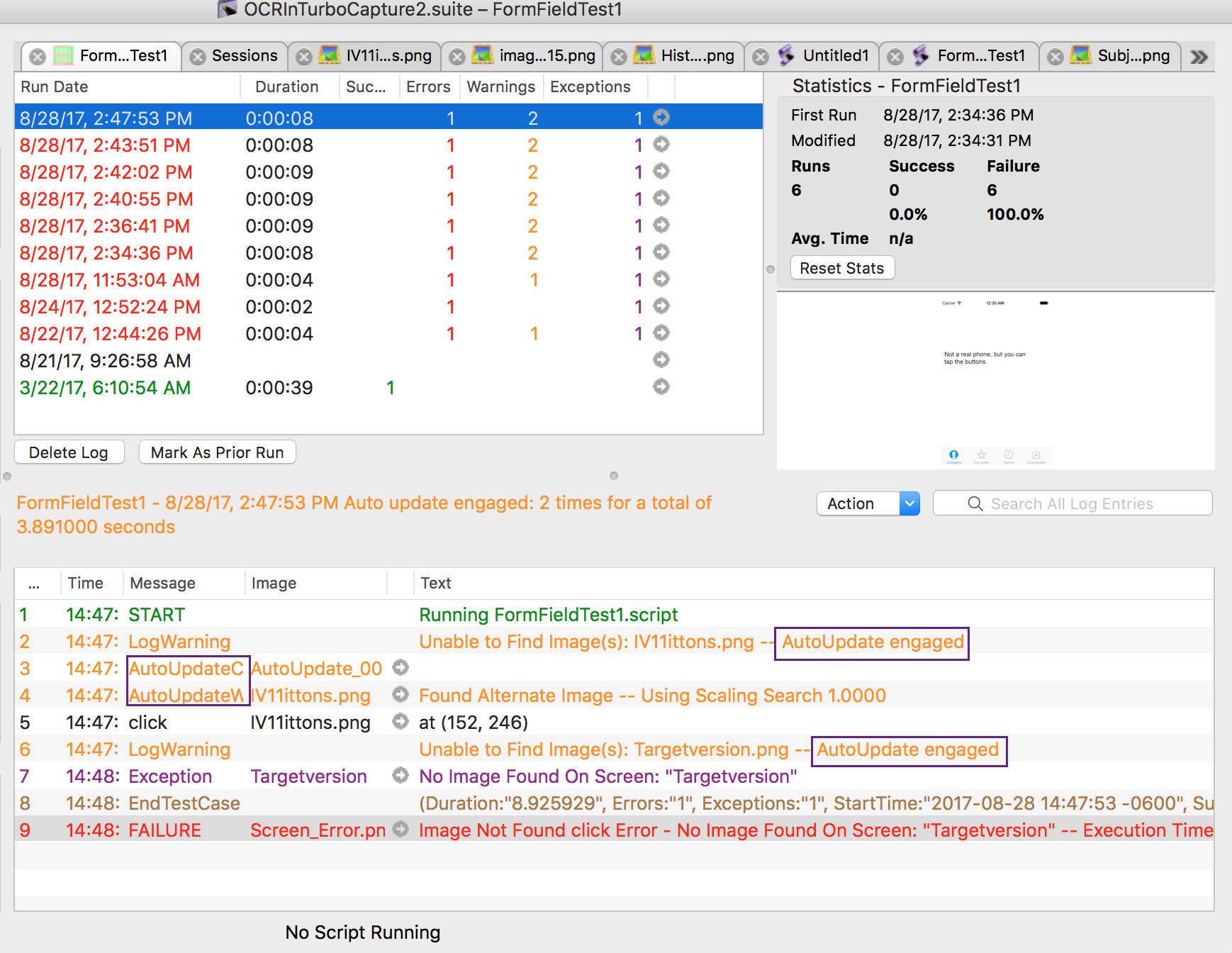
Preferencesでタイマーを調整することができます。Eggplant > Preferences > Run > Systemに移動します。Auto-proceed countdown on Image/OCR Updateセクションで、Auto-proceed Delayフィールドに所望の時間(秒)を入力します。値に0を使用すると、タイマーは全く表示されず、手動のOCR更新パネルは自動的にスクリプトに戻りません。
スタートタブ
Startタブは、OCRテキスト検索が失敗したときにパネルの最初の部分を表示します。このタブは、OCR検索パラメータを調整するのを助けるいくつかの診断ツールを提供します。
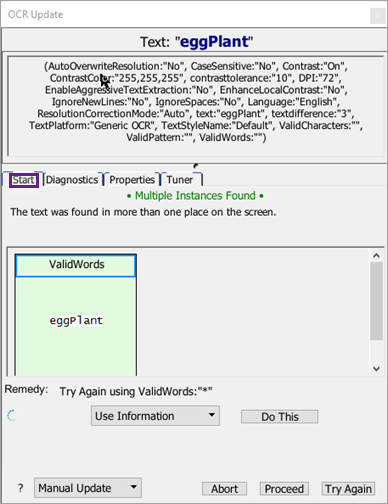
ウィンドウの上部には、失敗した検索からのテキスト文字列が表示されます。テキスト文字列の下には、検索に使用されたパラメータのリストが表示されます。
コード内に明示的にパラメータを含めていなくても、特定のパラメータはデフォルトとして仮定されるため、このリストは使用されたものを正確に表示します。
OCR更新パネルが開くと、Startタブにはカウントダウンタイマーが表示されることがあります。何も行動を取らない場合、パネルは閉じてカウントダウンが終了した後にスクリプトが続行されます。これは非監視のスクリプト実行に役立つことがあります。ただし、スクリプトが失敗した検索の例外を処理する準備ができていない場合、スクリプトは続行した後に失敗します。
異なるタブにアクセスするボタンの下には、OCRテキスト検索が失敗したときに取れる行動がウィンドウの下半分に表示されます。ドロップダウンメニューには主に2つの選択肢が表示されます:
- Use Information: 診断検索が潜在的な一致を見つけると、その情報を使ってスクリプトに検索を再試行させることができます。パネルの上部で診断を選択し、ドロップダウンリストからUse Informationを選択してDo Thisをクリックします。スクリプトは、指示されたパラメータを一時的に使用して元の検索を再度実行することで実行を再開します。実際のスクリプトコードは変更されません。
- Copy Information: パネルの上部で成功した診断を選択し、ドロップダウンリストからCopy Informationを選択することもできます。この操作により、パラメータがクリップボードにコピーされ、パラメータが将来の一致に役立つと判断した場合にスクたのですぐにスクリプトを更新できます。
このOCR検索に対してどのアクションを取るかを選択した後、選択したアクションをテストするためにDo Thisをクリックします。
The Diagnostics Tab
Diagnosticsタブは、テキスト文字列をOCR検索で画面上に見つけるために何が調整できるかを見るためのさまざまな診断検索を示します。
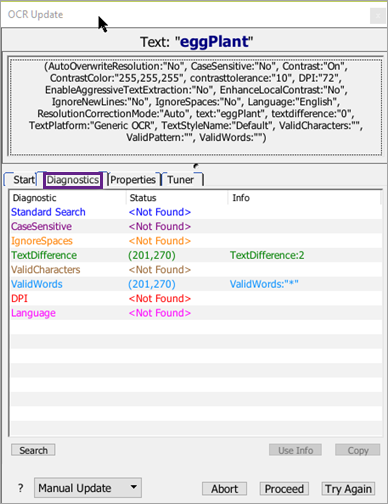
Status列は、パラメータで一致が見つからなかった場合は<Not Found>を表示し、可能な一致が見つかった場合は一致についての情報を表示します。これには複数の一致も含まれます。Info列は、一致が可能な場所で一致を作るために必要なパラメータ値を表示します。
実施される診断検索は次のとおりです:
- Standard: 元の仕様を使用してテキストを再検索します。この検索の結果は、最初にそれを見つけることができなかった後にテキストが表示されていることを意味します。ほとんどの場合、これはステップのスクリプ�トのタイミングを調整して、目的のテキストが表示されるのにもっと時間をかける必要があることを意味します。
- CaseSensitive: OCRテキスト検索はデフォルトでは大文字と小文字を区別しません。
caseSensitiveプロパティを使用して検索を大文字と小文字を区別して行い、テキスト文字列の大文字化に完全に一致する結果のみを返すように強制することができます。ほとんどの場合、診断はあなたのスクリプトがcaseSensitive: yesを指定した場合にのみ成功した一致を示し、その場合、検索が大文字小文字を区別しない場合に一致が可能であるかもしれません。 - IgnoreSpaces: この診断は、検索対象のテキスト文字列やSUTスクリーン上の潜在的な一致における空白スペースを無視して一致を探します。例えば、検索文字列が「Eggplant」である場合、OCRエンジンは「Egg plant」または「Eggplant」のどちらにも一致します。このパラメータはデフォルトでOCRテキスト検索にオンになっているため、診断は一般的にスクリプト内で
ignoreSpaces:"No"を使用した場合にのみ可能な一致を示します。 - TextDifference: この診断は、元の文字列と異なる個々の文字を持つことができるテキストを探して一致を見つけようとします。このパラメータは有用な場合があります。なぜなら、OCRエンジンは画面上のテキストを誤読することがあり、例えば、0をOと間違えることがあるからです。「テキストの違い」は、検索文字列と画面上に見つかったテキストの間で正確な一致を作るために変更する必要がある文字の数です。
- ValidCharacters:
ValidCharactersパラメータは、OCRエンジンが認識する文字を制限します。デフォルトでは、エンジンは現在のテキストプラットフォームの言語(または言語)の全文字セットを使用します。時々、文字を制限することで、エンジンにテキスト文字列を「見る」ように強制することができます。ワイルドカードとしてアスタリスクを使用できます。validCharacters:"*"で、OCRエンジンは元のテキスト文字列の文字のみを探します。 - ValidWords:
ValidWordsパラメータは、OCRエンジンが認識する単語を制限します。デフォルトでは、エンジンは現在のテキストプラットフォームの言語(または言語)の全単語セットを使用します。時々、単語を制限することで、エンジンにテキスト文字列を「見る」ように強制することができます。ワイルドカードとしてアスタリスクを使用できます。validWords:"*"で、OCRエンジンは元のテキスト文字列の単語のみを探します。validWordsパラメータはLanguage propertyを上書きします。この上書きにより、validWordsプロパティの一部でない単語は、ReadText()関数によって返されません。 - DPI: デフォルトではOCR検索は検索に72 DPIを使用します。しかし、SUTの解像度が大幅に異なる場合、DPIパラメータを使用して検索の解像度を別のものに設定することで、テキストを見つけることができるかもしれません。
- Language: この診断は、デフォルトのテキストプラットフォーム以外の��言語設定で一致が見つかる可能性があることを示します。
診断検索が潜在的な一致を見つけると、その情報を使用してスクリプトが再度検索を試みることができます。リストの中から診断を選択し、Use Infoをクリックし、次にTry Againをクリックします。スクリプトは、指示されたパラメータを一時的に使用して元の検索を再度実行することで実行を再開します。実際のスクリプトコードは変更されません。
成功した診断を選択し、Copyをクリックすると、指示されたパラメータがクリップボードにコピーされます。これにより、そのパラメータが将来の一致に役立つと判断した場合、スクリプトを簡単に更新できます。
SUTの条件を変更した場合、またはOCR更新パネルのPropertiesタブで検索オプションを変更した場合は、Searchボタンをクリックして新しい検索を作成し、診断を更新します。
プロパティタブ
Propertiesタブでは、OCR検索の異なるパラメータを試すことができます。また、一致が見つかるかどうかを確認するために、パラメータの組み合わせを試すこともできます。
Diagnosticsタブにリストされている各パラメータは、Propertiesタブでも利用できます。
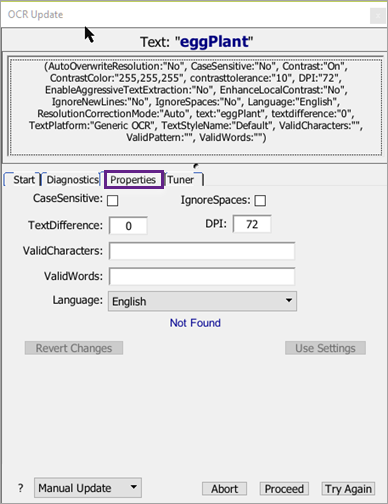
値を変更すると、スクリプトからの元の値が赤字で変更したフィールドの隣に表示されます。フィールドの下部には、青字で新しい値を使用した結果が表示されます。変更は累積されるので、複数のプロパティを変更すると、それぞれが検索に適用されてマッチングを試みます。
選択した新しいパラメータでスクリプトを再開したい場合は、Use SettingsをクリックしてからTry Againをクリックします。スクリプトは、指定したパラメータを一時的に使用して元の検索を再度実行し、再開します。実際のスクリプトコードは変更されません。
The Tuner Tab
Tunerタブには、OCR検索を改善するために微調整できるパラメータがリストされています。SenseTalkには、OCR検索を変更するためのいくつかのプロパティがあります。すべてのOCRプロパティを理解するために時間をかけて、適切な調整を行い、テスト環境での検索結果を改善できるようにしてください。ここに示されている情報を使用して、OCR検索を解決または改善します:
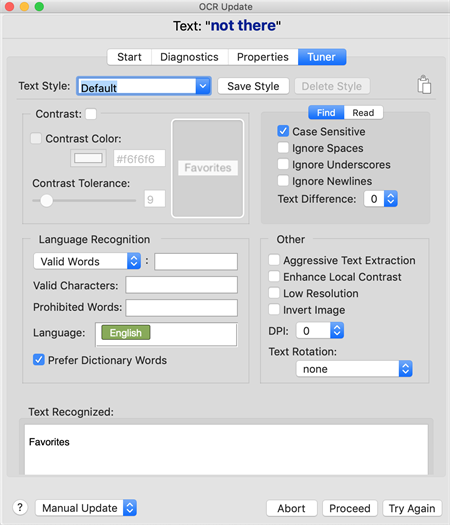
Text Not Found Area
パネルの最上部には、失敗したコードラインで検索していたテキスト文字列が表示されます。
Text Style
テキストスタイルとは、Eggplant Functionalのテキスト設定、OCRチューナー、またはOCR更新パネルで定義されたテキストプロパティのセットを保存したものです。各テキストスタイルは通常、テスト対象のアプリケーションで繰り返し出会う特定のフォントやGUI要素、例えばメニューアイテムやタイトルバーに特化したものです。テキストスタイルはOCR検索とReadText()の両方に適用することができます。読み取りと検索の違いについての詳細は、How to Use OCRをご覧ください。
パネルはデフォルトのスタイルが選択された状態で開きます。このセクション以下のOCRプロパティ�を変更すると、現在のスタイルが変更されます。この新しいスタイルを保存するには、Text Styleドロップダウンメニューで"Default"という単語を選択して名前を変更するか、上書きするスタイルを選択します(Defaultスタイルも変更可能です)。Save Styleをクリックします。
現在選択しているスタイルを削除するには、Delete Styleをクリックします。このオプションは、Defaultスタイルが選択されているときには無効になります。
このセクションの右側には、コピーアイコンがあります。これは、次のセクションで設定した現在のテキストプロパティをスクリプトで使用するためにコピーするために使用できます。詳しくはSave or Copy Property Settingsをご覧ください。
Contrast Section
Contrastセクションでは、Contrastプロパティと関連プロパティを設定し、操作することができます。Contrast設定は、システムアンダーテスト(SUT)の画像をOCRが取得し、それをOCRエンジンが認識する前に白黒に変換します。この対話型セクションには、右側にライブ更新エリアがあり、現在の検索矩形がViewer windowに描かれ、現在のContrast設定でOCRエンジンに送信される様子を示します。
-
Contrast: SUTの表示がOCRに送られる前に高コントラストの二色画像に変換されるかどうか。
contrastがオン�の場合、"contrast color"(ContrastColorプロパティを使用して設定できます)と呼ばれる色がSUT表示の主色とされ、他のすべての色は副色として扱われます。テキストはどちらの色でも見つけることができます。Contrastプロパティは、テキストの検索(検出)と読み取りの両方に使用できます。- Contrast Color:
Contrastがオンの場合、コントラストカラーはSUTの表示の主色とされ、他のすべての色は副色として扱われます。背景色の見つけ方については、Determining the Background Colorを参照してください。 - Contrast Tolerance:
Contrastがオンの場合、contrastToleranceは、ピクセルがコントラストカラーとして認識されるための最大チャネルごとの色差を設定します。
- Contrast Color:
The Find Tab
パネルの右上の四分の一には、FindとReadの2つのタブがあります。これは、OCRを使用して特定の文字列を検索するか、SUTの画面から未知のテキストを読み取ることができるためです。一部のプロパティは、テキストを読むときか、テキストを検索するときだけ使用できます。Findタブは、特定の文字列を検索するときに設定できる次のプロパティを表示します。読むと見つけるの違いについては、How to Use OCRをご覧ください。
Ignore Spaces: ignoreSpacesプロ�パティは、OCRテキスト検索がテキスト文字列内のスペースを無視するようにします。例えば、文字列"My Computer"は"MyComputer"や"M y C o m p u t e r"と一致します。ignoreSpacesプロパティはデフォルトでオンになっています。これは、OCRが意図的でないスペースを読み取ることがあるため、特に離散的な単語ではない文字列や、文字間隔が不規則なテキストで起こります。
Ignore Underscores: ignoreUnderscoresプロパティは、OCRテキスト検索がアンダースコアを検索中にスペースとして扱うようにします。例えば、文字列"My_Computer"は"My_Computer"または"My Computer"と一致します。ignoreUnderscoresプロパティはデフォルトでオンになっています。これは、OCRがアンダースコアを認識しないことがあるためです。
Ignore Newlines: 有効にすると、ignoreNewlinesはOCRテキスト検索が改行を無視するようになり、検索は複数の行に分割された文字列と一致します。このプロパティはテキスト検索でのみ利用可能で、ReadTextでは利用できません。
The Read Tab
パネルの右上の四分の一には、FindとReadの2つのタブがあります。これは、OCRを使用して特定の文字列を検索するか、SUTの画面から未知のテキストを読み取ることができるためです。一部のプロパティは、テキストを読むときか、テキストを検索するときだけ使用できます。Readタブは、システムテスト中の画面からテ��キストを読み取るときに設定できる次のプロパティを表示します。読むと見つけるの違いについては、How to Use OCRをご覧ください。
Trim Whitespace: TrimWhitespaceがオンの場合、返されるテキストの先頭と末尾からすべての空白文字が削除されます。TrimWhitespaceがオフの場合、ReadText functionは空白文字で始まるか終わるテキストを返すことができます。これは、既知の文字列の検索ではなく、テキストの読み取りにのみ使用します。
Multi-Line: このプロパティは、矩形内のテキストを読み取るのではなく、点付近のテキストを読み取る際にのみ適用されます。MultiLineがオンの場合、ReadText functionは、指定した点に関連するテキスト行と、それが同じテキストブロックに属していると思われる点の上下のテキスト行を返します。MultiLineがオフの場合、ReadText関数は点に関連するテキスト行のみを返します。
Language Recognition
言語設定を操作することで、OCR検索に多くの変更を加えることができます。デフォルトではOCRは言語辞書を使用しませんが、辞書を指定したり修正したりすることができますし、Custom OCR Dictionaryを作成することも可能です。��このセクションのすべてのOCR Propertiesは、定義済みのOCR Languagesの1つを使用してLanguageプロパティを設定するか、有効とするべき単語や文字を指定する(他のすべてのマッチを排除する)、マッチングに出てくる可能性のある特定の単語を禁止する、またはパターンを操作するか、どちらかに関連して言語と連携します。
Valid Wordsドロップダウンメニュー:
このドロップダウンメニューには、設定できる5つの異なるプロパティがリストされています。これらは相互排他的で、一度に設定できるのは1つだけで、そのプロパティに提供する値は、このメニューの右側のテキストフィールドに入力します。
- Valid Words: OCRがマッチと見なすことができる単語を制限することで、OCRエンジンを成功したマッチに向けて誘導するか、エンジンにテキスト文字列を正しく認識させることができます。アスタリスク(*)をワイルドカードとして使用して、OCRエンジンが元のテキスト文字列の単語だけを探すようにすることができます。このプロパティはOCRテキストエンジンが見つけることができる単語を制限します。詳しくは、Customize the OCR Engine Dictionaryをご覧ください。
validWordsプロパティはLanguageプロパティを上書きします。この上書きは、validWordsプロパティの一部でない単語は返されないことを意味します。 - Preferred Words: このプロパティを特定の単語リストに設定することで、現在の言語の組み込み辞書を補完します。
PreferredWordsはテキストの読み取りまたは検索のどちらにも使用できます。このプロパティはOCR辞書を変更します。詳細は、Customize the OCR Dictionaryをご覧ください。 - Valid Pattern: このプロパティは正規表現の値を取り、指定されたパターンと一致する文字や単語のみを返します。SenseTalkで使用できる正規表現の文字については、Using Patterns in SenseTalkをご覧ください。パターンをOCRに優先させたいが必須にはしたくない場合は、PreferredPatternを参照してください。
- Preferred Pattern: このプロパティが有効になっていて正規表現の文字列が与えられると、OCRは提供されたパターンに一致するテキストを優先します。SenseTalkで使用できる正規表現の文字については、Using Patterns in SenseTalkをご覧ください。OCRにパターンマッチを必須にしたい場合は、ValidPatternを使用してください。
- Extra Words: このプロパティを現在の言語の組み込み辞書を補完する単語のリストに設定します。これらの単語は他の辞書の単語と同様に優先されます。
その他のセクション
これらのOCRプロパティは頻繁には使用されませんが、適切なシナリオでは役立つことがあります。
Enhance Local Contrast: OCRに送信されるテキスト画像の局所的なコントラストを自動的に増加させたい場合は、このプロパティを有効にします。このプロパティは、読み取り対象のテキストの一部または全部が相対的にコントラストが低い(例えば、暗い背景上の青いテキストなど)場合、認識を助ける可能性があります。Contrastがオンのときは、このプロパティは無効になるため、Contrastがオフのときにのみ有用です。
Low Resolution: OCRエンジンがEggplant Functionalから受け取る画像を低解像度(実際には画像は低解像度に変換されません)として処理する処理モード。これにより、OCRが小さな文字を認識するのに役立つ可能性があります。
Invert Image: OCRがテキスト画像の色を反転(写真ネガティブのように)させてから、それをOCRエンジンに送信するためにこのプロパティを有効にします。
Aggressive Text Extraction: 画像から可能な限り多くのテキストをOCRで抽出したい場合は、このプロパティを有効にします。
DPI: DPIプロパティは、SUTディスプレイのDPI(ドット/インチ)を指します。SUTでテキストを見つけるのに問題がある場合は、SUTのDPI設定を確認し、DPIプロパティをそれに応じて調整してください。
Text Rotation: このプロパティが設定されると、OCRは、事前�に定義された値で指定された回転角度で単語を識別します:Clockwiseは右に90度回転します;Counter-clockwiseは左に90度回転します;Upside-downは180度回転します;Noneはテキストを回転させません。テキストの読み取りと検索の両方に使用できます。
Text Recognized Area
このエリアは、パネルの上部エリアで提供した設定を使用して、ビューアウィンドウの現在のキャプチャエリアで読み取られているテキストを表示します。これはライブ更新です。